【人工智能项目】LSTM实现电影评论情感分类实验_堆栈lstm情感分析-程序员宅基地
技术标签: 人工智能 机器学习 深度学习 lstm 人工智能 项目篇 分类
【人工智能项目】LSTM实现电影评论情感分类实验
本次对电影评论的情感进行分析,看是否为积极评论还是消极评论。

本次所用数据集
import os
data_dir = "./Dataset"
print(os.listdir(data_dir))
['test.txt', 'train.txt', 'validation.txt', 'wiki_word2vec_50.bin']
导包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
import time
import datetime
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.utils import class_weight as cw
from keras import Sequential
from keras.models import Model
from keras.layers import LSTM,Activation,Dense,Dropout,Input,Embedding,BatchNormalization,Add,concatenate,Flatten
from keras.layers import Conv1D,Conv2D,Convolution1D,MaxPool1D,SeparableConv1D,SpatialDropout1D,GlobalAvgPool1D,GlobalMaxPool1D,GlobalMaxPooling1D
from keras.layers.pooling import _GlobalPooling1D
from keras.layers import MaxPooling2D,GlobalMaxPooling2D,GlobalAveragePooling2D
from keras.optimizers import RMSprop,Adam
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.utils import to_categorical
from keras.callbacks import EarlyStopping
from keras.callbacks import ModelCheckpoint
from keras.callbacks import ReduceLROnPlateau
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
Using TensorFlow backend.
导入数据
train_df = pd.read_csv("./Dataset/train.txt",encoding="utf-8",header=None,sep="\t",names=["label","text"])
valid_df = pd.read_csv("./Dataset/validation.txt",encoding="utf-8",header=None,sep="\t",names=["label","text"])
test_df = pd.read_csv("./Dataset/test.txt",encoding="utf-8",header=None,sep="\t",names=["label","text"])
train_df
| label | text | |
|---|---|---|
| 0 | 1 | 死囚 爱 刽子手 女贼 爱 衙役 我们 爱 你们 难道 还有 别的 选择 没想到 胡军 除了... |
| 1 | 1 | 其实 我 对 锦衣卫 爱情 很萌 因为 很 言情小说 可惜 女主角 我要 不是 这样 被 乔... |
| 2 | 1 | 两星 半 小 明星 本色 出演 老 演员 自己 发挥 基本上 王力宏 表演 指导 上 没有 ... |
| 3 | 1 | 神马 狗血 编剧 神马 垃圾 导演 女 猪脚 无 胸无 人 胃口 一干 男 猪脚 基情 四射... |
| 4 | 1 | Feb 半顆 星 我們 家 說 這是 一部 從 開始 第十二 分鐘 我 開始 打哈欠 一直 ... |
| ... | ... | ... |
| 19993 | 0 | 齐齐 像 一幅 油彩 色彩 绚烂 青春 斑斓 栗子 姐姐 女神 般的 存在 多少 女孩 幻想... |
| 19994 | 0 | 使 我 想起 多年 前 看 精武 英雄 叙事 按部就班 打斗 倒 精彩 刺激 也 颇 能 安... |
| 19995 | 0 | 看 之前 豆瓣 上 看到 一个 评论 说 要 找到 自己 看 这部 电影 哭泣 原因 我 想... |
| 19996 | 0 | 假如 影片 大前提 逻辑 完全 成立 那么 影片 前后 呼应 节奏 情节 主题 简直 完美 ... |
| 19997 | 0 | 一种 浪漫 能 让 美女 感动 两种 浪漫 却 能 让 美女 不知所措 房子 车子 足以 让... |
19998 rows × 2 columns
# 重新排序
train_df = train_df.sample(frac=1).reset_index(drop=True)
train_df
| label | text | |
|---|---|---|
| 0 | 0 | 一直 一来 我 认为 最好 电影 之一 基本上 一段时间 翻出来 看一遍 感动 那么 多 人... |
| 1 | 0 | 哭 很 感触 鬼 经历 真的 好像 好像 虽然 最后 回到 现实 但是 他们 精神 留下 鬼... |
| 2 | 0 | 依旧 不用 看前 部 能 看 懂 美式 剧情 特效 制作 相当 精细 阿汤哥 迪拜 一系列 ... |
| 3 | 0 | 好 电影 不 需要 大 成本 好 电影 只 需要 打动 你 一点 东西 很 喜欢 这样 大家... |
| 4 | 1 | 王宝强 农民 但 这部 戏里 不是 傻根 为什么 非要 演 跟 年代 傻根 一样 你 见 过... |
| ... | ... | ... |
| 19993 | 0 | 不管 别人 怎么样 抨击 我 心里 这是 一部 好 电影 爱 恨 感觉 情到 深处 贝尔 演... |
| 19994 | 0 | 一部 故事情节 太 完整 主题 太 直接 有点 脱离 新海 诚 以往 风格 中间 部分 感觉... |
| 19995 | 1 | 其实 世界 上本 没有 火星 男 女人 普遍 认可 并 接受 花心 不负责任 只用 下半身 ... |
| 19996 | 0 | 成龙 终于 一部 没有 成龙 风格 电影 尔冬升 用 很 重 力 直面 人性 贪婪 生存 面... |
| 19997 | 1 | 一部 完全 扯淡 B 级片 唯一 让 我 提起 精神 那个 硕大 毛 爷爷 头像 好 我 准... |
19998 rows × 2 columns
valid_df
| label | text | |
|---|---|---|
| 0 | 1 | 台湾 导演 执导 林志玲 一人 分饰两角 扮演 一对 双胞胎 姐妹 廖凡 陈坤 杨佑宁 出演... |
| 1 | 1 | 我 一向 主张 文艺片 商业片 区别对待 需要 用 不同 标准 来 衡量 英雄 无极 我 认... |
| 2 | 1 | 比较 失望 本 以为 冯是 国内 导演 中 最会 讲故事 一个 结果 中途 因为 吃 太饱 ... |
| 3 | 1 | 改编 很 失败 把 莎 老公 改成 个 中年 带 儿子 大叔 给 两人 美好 结局 本书 本... |
| 4 | 1 | 剧情 一直 没看 懂 看到 一半 时 女友 旁 笑 说 演 电影 疯子 看 电影 傻子 老实... |
| ... | ... | ... |
| 5624 | 0 | 看不懂 棒球 规则 以及 数据 理论 情况 下 仍然 交杂 激动 播报 连胜 结果 眼眶 皮... |
| 5625 | 0 | 笑點 還挺 多 但 又 不是 無厘頭 那種 不知 所謂 戲中 四個 故事 還挺 有意思 至於... |
| 5626 | 0 | 其实 电视剧 比 电影版 不 知道 强 多少倍 起码 王 珞丹 很 适合 杜 拉拉 这个 角... |
| 5627 | 0 | 这是 一部 给 后 看 片子 对于 整日 大城市 里 工作 奔波 还要 担心 明儿 会 不会... |
| 5628 | 0 | 出 电影 前 看 那个 MV 万分 期待 觉得 女生 太 帅气 可是 看 又 觉得 好像 没... |
5629 rows × 2 columns
# 重新排序
valid_df = valid_df.sample(frac=1).reset_index(drop=True)
valid_df
| label | text | |
|---|---|---|
| 0 | 0 | 真的 很 搞笑 虽然 很多 场景 比较 暴露 比较 赤裸裸 但是 看 时候 完全 没有 觉得... |
| 1 | 0 | 好看 不是 净 追求 大 场面 古装片 更 多 桌子 底下 暗流 涌动 那根 弦 时时 令人... |
| 2 | 0 | 值得一看 印度 贫民窟 种种 感情 面对 生活 不同 抉择 随着 一个个 问题 慢慢 展现 ... |
| 3 | 1 | 分钟 其实 剪辑版 剧情 节奏 这么 莫名其妙 不要 以为 结局 其他人 全灭 两个 男人 ... |
| 4 | 1 | 片子 看得 我 直起 鸡皮疙瘩 那群 多毛 强壮 未开化 猩猩 竟然 比 人类 还要 聪明 ... |
| ... | ... | ... |
| 5624 | 0 | 经典台词 地球 上 热带雨林 目前 正以 每秒钟 相当于 两个 场 速度 消失 造成 每天 ... |
| 5625 | 0 | 以 小说 改编 不管 十三 钗 这事 真是假 我们 南京城 三十万 同胞 确是 真真实实 牺... |
| 5626 | 0 | 一切 淡淡的 爱 无奈 滔滔 巨浪 般 对 金鱼 公主 爱恋 之后 宫崎 爷爷 转而 描画 ... |
| 5627 | 0 | 如果说 四 奶奶 大 奶奶 天生 敌人 那么 柴 九 就是 天生 知己 他们 之间 应该 不... |
| 5628 | 1 | 天天 里 出现 每个 演员 当 电影 好不好 先不说 做法 让 人 反 感到 作呕 本来 想... |
5629 rows × 2 columns
test_df
| label | text | |
|---|---|---|
| 0 | 1 | 如果 我 无聊 时 网上 乱逛 偶尔 看到 这部 电影 我 可能 会 给 它 打 四星 但是... |
| 1 | 1 | 服装 很漂亮 场景 很大 气 演员 演得 也 不错 特技 效果 也 非常 精彩 魔幻 味 够... |
| 2 | 1 | 冯小刚 越来越 会 摸 国人 卖 搞 人 还有 很多 傻 跟着 转 个人 认为 完全 个 喜... |
| 3 | 1 | 该剧 还是 正 老 问题 就是 痕迹 过重 宫廷 剧是 最受 观众 欢迎 所以 人人 来 拍... |
| 4 | 1 | 戏 不够 误会 凑 戏 不够 人妖 凑 戏 不够 卧底 凑 戏 不够 寻宝 凑 戏 不够 野... |
| ... | ... | ... |
| 364 | 0 | 像 多年 前 朋友 說 一樣 法國人 浪漫 總讓 人覺 他們 心裡 綻 滿 花 如果 每天 ... |
| 365 | 0 | 看 这部 片子 时候 我 一直 想 这种 影片 属于 什么 类型 影片 开始 部分 普通人 ... |
| 366 | 0 | 阿娇 从 啥子 时候 那么 漂亮 演技 也好 看来 就是 要 赤裸裸 经历 才 真的 体验 ... |
| 367 | 0 | 没有 华丽 镜头 或者 刻意 营造 小 清新 就是 普普通通 台湾 巷子 简简单单 中学 教... |
| 368 | 0 | 我 从来不 认为 个人 应当 集体 社会 而 赎罪 你 可以 说 没有 个人 忏悔 没有 集... |
369 rows × 2 columns
# 重新排序
test_df = test_df.sample(frac=1).reset_index(drop=True)
test_df
| label | text | |
|---|---|---|
| 0 | 0 | 原来 这部 戏 黑暗 对 观看 者 精神 摧残 逼迫 我们 去 思考 科技 网络 技术 发展... |
| 1 | 1 | 实在 不 明白 就是 他们 说 非常 感人 电影 任何 情节 上 硬伤 或者 我 认为 硬伤... |
| 2 | 1 | 残 不忍 睹 看 个 开头 实在 坚持 不了 精虫 吃光 他们 大脑 东京 热 正式 后 新... |
| 3 | 0 | 未来 房屋 架构 思想 不管 动画 还是 真人 电影 想要 表现 这种 温情 手段 并 不 ... |
| 4 | 1 | 对 维多利亚 爱情 萌生 过渡 太硬 她 动人 处 究竟 一度 产生 这样 感觉 吸引 基努... |
| ... | ... | ... |
| 364 | 0 | 当人 落魄 时候 检验 一个 人 真正 时刻 兄弟 情义 男人 与 男人 之间 对决 能屈能... |
| 365 | 1 | 刘导 拍 这个 您 就是 晚节不保 就算 看看 后面 那些 乱七八糟 差一 杠子 人 我 恶... |
| 366 | 1 | 祢 丫 昰 就算 讓 我 淚 撒 奧斯卡 祢 也 昰 部爛片 前半部 男人 拯救 苦海 小三... |
| 367 | 0 | 很 经典 恐怖片 结局 很 出乎意料 我 看 好几遍 发现 不少 感人 地方 也 去 思考 ... |
| 368 | 0 | 我 唯一 愿意 给 满分 片子 诺兰 片子 虽然 很 主观 但是 我 喜欢 他 叙事 喜欢 ... |
369 rows × 2 columns
print(train_df.shape,valid_df.shape,test_df.shape)
(19998, 2) (5629, 2) (369, 2)
valid_df = pd.concat([valid_df,test_df[:50]],axis=0)
# 合并
train_df = pd.concat([train_df,valid_df],axis=0)
print(train_df.shape)
(25677, 2)
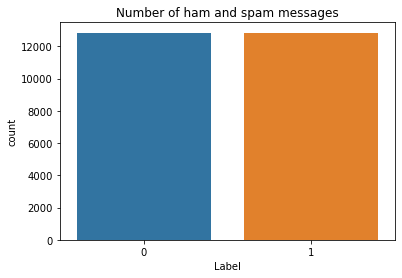
# 统计一下
sns.countplot(train_df["label"])
plt.title("Number of ham and spam messages")
plt.xlabel("Label")
Text(0.5, 0, 'Label')
标签数据处理
# 对标签进行处理
# LabelEncoder 是对不连续的数字或者文本进行编号
# LabelEncoder可以将标签分配一个0—n_classes-1之间的编码
x_train = train_df["text"]
y_train = train_df["label"]
le = LabelEncoder()
y_train = le.fit_transform(y_train)
y_train = y_train.reshape(-1,1)
文本数据处理
# 分词器Tokenizer Tokenizer是一个用于向量化文本,或将文本转换为序列(即单词在字典中的下标构成的列表,从1算起)的类
# 类方法
# fit_on_texts(texts) :texts用于训练的文本列表
# texts_to_sequences(texts):texts待转为序列的文本列表 返回值:序列的列表,列表中的每个序列对应于一段输入文本
# 填充序列pad_sequences 将长为nb_smaples的序列转换为(nb_samples,nb_timesteps)2Dnumpy attay.如果提供maxlen,nb_timesteps=maxlen,
#否则其值为最长序列的长度。
# 其它短于该长度的序列都会在后部填充0以达到该长度。长与nb_timesteps的序列会被阶段,以使其匹配该目标长度。
#max_words = 1000
#max_len = 150
max_words = len(set(" ".join(x_train).split()))
max_len = x_train.apply(lambda x:len(x)).max()
tok = Tokenizer(num_words=max_words)
tok.fit_on_texts(x_train)
sequences = tok.texts_to_sequences(x_train)
sequences_matrix = sequence.pad_sequences(sequences,maxlen=max_len)
-
ModelCheckpoint:
- 作用:该回调函数将在每个epoch后保存模型到filepath
- 参数:
- filename:字符串,保存模型的路径,filepath可以是格式化的字符串,里面的
- monitor:需要监视的值,通常为:val_acc或val_loss或acc或loss
- verbose:信息展示模型,0或1。默认为0表示不输出该信息,为1表示输出epoch模型保存信息。
- save_best_only:当设置为Trur时,将只保存在验证集上性能最好的模型
- mode:“auto”,“min”,"max"之一,在save_best_only=True时决定性能最佳模型的评判准则。
- save_weights_only:若设置为True时,则只保存模型权重,否则将保存整个模型(包括模型结构,配置信息等)
- period:CheckPoint之间的间隔的epoch数
-
EarlyStopping:
- 作用:当监测值不再改善时,该回调函数将中止训练
- 参数:
- monitor:需要监视的量,通常为val_acc或val_loss或acc或loss
- patience:当early stop被激活(如发现loss相比上patience个epoch训练没有下降),则经过patience个epoch后停止训练。
- verbose:信息展示模型
- mode:“auto”,“min”,"max"之一,在min模式下,如果检测值停止下降则中止训练。在max模式下,当检测值不再上升则停止训练。
-
ReduceLROnPlateau:
- 作用:当评价指标不再提升时,减少学习率。当学习停滞时,减少2倍或10倍的学习率通常能够获得较好的效果。该回调函数检测指标的情况,如果在patience个epoch中看不到模型性能提升,则减少学习率。
- 参数:
- monitor:被监测的量
- factor:每次减少学习率的因子,学习率将以lr=lr*factor的形式被技术那好
- patience:当patience个epoch过去而模型性能不提升时,学习率减少的动作会被触发
- mode:“auto”,“min”,"max"之一,在min模式下,如果检测值触发学习率减少。在max模式下,当检测值不再上升则触发学习率减少
- epsilon:阈值,用来确定是否进入检测值的“平原区”
- cooldown:学习率减少后,会经过cooldown个epoch才重新进行正常操作
- min_lr:学习率的下限。
print("Setting Callbacks")
checkpoint = ModelCheckpoint("model.h5",
monitor="val_acc",
verbose=1,
save_best_only=True,
mode="max")
early_stopping = EarlyStopping(monitor="val_loss",
patience=3,
verbose=1,
restore_best_weights=True,
mode="min")
reduce_lr = ReduceLROnPlateau(monitor="val_loss",
factor=0.5,
patience=2,
verbose=1,
mode="min")
callbacks=[checkpoint,early_stopping,reduce_lr]
Setting Callbacks
定义深度学习模型
# 定义RNN模型
def RNN():
model = Sequential()
model.add(Embedding(max_words,128,input_length=max_len))
model.add(LSTM(64))
model.add(Dropout(0.5))
model.add(BatchNormalization())
model.add(Dense(256,activation="relu"))
model.add(Dropout(0.5))
model.add(BatchNormalization())
model.add(Dense(64,activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(1,activation="sigmoid"))
model.summary()
return model
# 画曲线
def plot_performance(history=None,figure_directory=None,ylim_pad=[0,0]):
xlabel="Epoch"
legends=["Training","Validation"]
plt.figure(figsize=(20,5))
y1=history.history["accuracy"]
y2=history.history["val_accuracy"]
min_y=min(min(y1),min(y2))-ylim_pad[0]
max_y=max(max(y1),max(y2))+ylim_pad[0]
plt.subplot(121)
plt.plot(y1)
plt.plot(y2)
plt.title("Model Accuracy\n",fontsize=17)
plt.xlabel(xlabel,fontsize=15)
plt.ylabel("Accuracy",fontsize=15)
plt.ylim(min_y,max_y)
plt.legend(legends,loc="upper left")
plt.grid()
y1=history.history["loss"]
y2=history.history["val_loss"]
min_y=min(min(y1),min(y2))-ylim_pad[1]
max_y=max(max(y1),max(y2))+ylim_pad[1]
plt.subplot(122)
plt.plot(y1)
plt.plot(y2)
plt.title("Model Loss:\n",fontsize=17)
plt.xlabel(xlabel,fontsize=15)
plt.ylabel("Loss",fontsize=15)
plt.ylim(min_y,max_y)
plt.legend(legends,loc="upper left")
plt.grid()
plt.show()
RNN
rnn_model = RNN()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 1954, 128) 7551616
_________________________________________________________________
lstm_1 (LSTM) (None, 64) 49408
_________________________________________________________________
dropout_1 (Dropout) (None, 64) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 64) 256
_________________________________________________________________
dense_1 (Dense) (None, 256) 16640
_________________________________________________________________
dropout_2 (Dropout) (None, 256) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 256) 1024
_________________________________________________________________
dense_2 (Dense) (None, 64) 16448
_________________________________________________________________
dropout_3 (Dropout) (None, 64) 0
_________________________________________________________________
dense_3 (Dense) (None, 1) 65
=================================================================
Total params: 7,635,457
Trainable params: 7,634,817
Non-trainable params: 640
_________________________________________________________________
loss = "binary_crossentropy"
metrics=["accuracy"]
# RNN模型训练
print("Starting...\n")
learning_rate=0.001
optimizer=Adam(learning_rate)
print("\n\nCompliling Model...\n")
rnn_model.compile(optimizer=optimizer,
loss=loss,
metrics=metrics)
verbose = 1
epochs=100
batch_size=128
validation_split=0.1
print("Trainning Model...\n")
rnn_history=rnn_model.fit(sequences_matrix,
y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
callbacks=callbacks,
validation_split=validation_split)
Starting...
Compliling Model...
WARNING:tensorflow:From D:\software\Anaconda\anaconda\envs\tensorflow\lib\site-packages\tensorflow\python\ops\nn_impl.py:180: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
Trainning Model...
WARNING:tensorflow:From D:\software\Anaconda\anaconda\envs\tensorflow\lib\site-packages\keras\backend\tensorflow_backend.py:422: The name tf.global_variables is deprecated. Please use tf.compat.v1.global_variables instead.
Train on 23109 samples, validate on 2568 samples
Epoch 1/100
23109/23109 [==============================] - 320s 14ms/step - loss: 0.6358 - accuracy: 0.6747 - val_loss: 0.6019 - val_accuracy: 0.8236
Epoch 2/100
23109/23109 [==============================] - 317s 14ms/step - loss: 0.2775 - accuracy: 0.8940 - val_loss: 0.4068 - val_accuracy: 0.8162
Epoch 3/100
23109/23109 [==============================] - 319s 14ms/step - loss: 0.1187 - accuracy: 0.9601 - val_loss: 0.4475 - val_accuracy: 0.8185
Epoch 4/100
23109/23109 [==============================] - 325s 14ms/step - loss: 0.0608 - accuracy: 0.9803 - val_loss: 0.9544 - val_accuracy: 0.7819
Epoch 00004: ReduceLROnPlateau reducing learning rate to 0.0005000000237487257.
Epoch 5/100
23109/23109 [==============================] - 325s 14ms/step - loss: 0.0285 - accuracy: 0.9904 - val_loss: 0.7304 - val_accuracy: 0.8209
Restoring model weights from the end of the best epoch
Epoch 00005: early stopping
# 可视化
plot_performance(history=rnn_history)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jeZVpTeF-1635930217671)(output_31_0.png)]](https://img-blog.csdnimg.cn/3856ba0a9ae7480e87d03c8943630593.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAbWluZF9wcm9ncmFtbW9ua2V5,size_20,color_FFFFFF,t_70,g_se,x_16)
验证结果
# 数据导入
data = pd.read_csv("./Dataset/test.txt",encoding="utf-8",header=None,sep="\t",names=["label","text"])
data.head()
| label | text | |
|---|---|---|
| 0 | 1 | 如果 我 无聊 时 网上 乱逛 偶尔 看到 这部 电影 我 可能 会 给 它 打 四星 但是... |
| 1 | 1 | 服装 很漂亮 场景 很大 气 演员 演得 也 不错 特技 效果 也 非常 精彩 魔幻 味 够... |
| 2 | 1 | 冯小刚 越来越 会 摸 国人 卖 搞 人 还有 很多 傻 跟着 转 个人 认为 完全 个 喜... |
| 3 | 1 | 该剧 还是 正 老 问题 就是 痕迹 过重 宫廷 剧是 最受 观众 欢迎 所以 人人 来 拍... |
| 4 | 1 | 戏 不够 误会 凑 戏 不够 人妖 凑 戏 不够 卧底 凑 戏 不够 寻宝 凑 戏 不够 野... |
y_test = data["label"]
y_test = np.array(y_test)
predict_data = data["text"]
# 将带预测数据转为序列
predict_sequences = tok.texts_to_sequences(predict_data)
predict_sequences_matrix = sequence.pad_sequences(predict_sequences,maxlen=max_len)
# RNN预测
rnn_predict_num = rnn_model.predict_classes(predict_sequences_matrix )
predict = rnn_predict_num[:,0]
predict
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1,
1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1,
1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0,
1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0,
0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0,
0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1,
0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1])
y_test
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int64)
from sklearn.metrics import accuracy_score
print(accuracy_score(predict,y_test))
0.8373983739837398
小结
点赞收藏评论走起来,亲爱的瓷们!!!!

智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范