akka和netty在flink和spark中的使用-程序员宅基地
【背景】
在flink和spark中,都有akka和netty的身影出现,对比着看能加深理解
akka和netty在flink和spark中的作用
Flink:
Flink内部节点之间的通信是用Akka,比如JobManager和TaskManager之间的通信(例如jm发送task给tm就是用akka)。而operator之间的数据传输是利用Netty。
Spark:
1.6版本之前Spark的通信机制只采用Akka通信框架;
1.6版本之后加入Netty通信框架,并通过配置的方式允许用户自定义使用哪种通信方式;
配置org.apache.spark.rpc.netty.NettyRpcEnvFactory 表示使用 netty
配置org.apache.spark.rpc.akka.AkkaRpcEnvFactory 表示使用 akka
2.0版本之后把Akka去掉,只保留了Netty,主要原因:
一、解决用户的Spark Application 中 Akka 版本和 Spark 内置的 Akka版本冲突的问题。很多Spark用户自己的应用程序中的通信框架也是使用Akka,但是由于Akka版本之间无法互相通信,这就要求用户必须使用跟Spark完全相同的版本,导致用户无法升级Akka。
二、Spark的Akka配置是针对Spark自身来调优的,可能跟用户自己代码中的Akka配置冲突。
三、Spark用的Akka特性很少,这部分特性很容易自己实现,灵活性强。
四、akka 是为了通信,不适合大数据量的传输,像hadoop flink hbase 这些后面都用netty 来做节点间数据的传输
RPC是什么
网络通信需要遵守相同的通信协议,RPC即远程过程调用协议,一种通过网络从远程计算机上请求服务而不需要了解底层网络传输技术的协议。
特点:
- 调用远程就像调用本地一样。 (其实就是屏蔽了细节)
- 网络协议和网络IO模型对RPC调用者透明
- 网络传输的信息格式对RPC调用者透明
akka和netty是什么?有什么区别
Akka:基于Actor的RPC通信系统;基于协程,性能好;基于scala的偏函数,易用性高。但它只是RPC通信,无法适用大的package/stream的数据传输,这也是Spark引入Netty来代替Akka的原因。
Netty:基于java NIO,相比更加基础一点,可以为不同的应用层通信协议(RPC,FTP,HTTP等)提供支持。
Akka
Akka最重要的是它的Actor模型。
Actor模型
在使用Java进行并发编程时需要特别的关注锁和内存原子性等一系列线程问题,而Actor模型内部的状态由它自己维护即它内部数据只能由它自己修改(通过消息传递来进行状态修改),所以使用Actors模型进行并发编程可以很好地避免这些问题,Actor由状态(state)、行为(Behavior)和邮箱(mailBox)三部分组成。
- 状态(state):Actor中的状态指的是Actor对象的变量信息,状态由Actor自己管理,避免了并发环境下的锁和内存原子性等问题
- 行为(Behavior):行为指定的是Actor中计算逻辑,通过Actor接收到消息来改变Actor的状态
Akka 行为是描述actor如何响应消息的不可变对象。它定义了actor在收到特定消息时应执行的操作。比如说一个计数器Actorr,它维护着一个整数计数,当接收到特定消息1时,他会做加法;当接收到特定消息2时,他会做减法;
- 邮箱(mailBox):邮箱是Actor和Actor之间的通信桥梁,邮箱内部通过FIFO消息队列来存储发送方Actor消息,接受方Actor从邮箱队列中获取消息。
Actor的基础是消息通信,使用Actor的优势:
(1)事件模型驱动--Actor之间的通信是异步的,即使Actor在发送消息后也无需阻塞或者等待就能够处理其他事情;
(2)强隔离性--Actor中的方法不能由外部直接调用,所有的一切都通过消息传递进行的,从而避免了Actor之间的数据共享,想要观察到另一个Actor的状态变化只能通过消息传递进行询问;
(3)位置透明--无论Actor地址是在本地还是在远程机上对于代码来说都是一样的;
(4)轻量性--Actor是非常轻量的计算单机,单个Actor仅占400多字节,只需少量内存就能达到高并发。
在Actor模型中,所有的实体被认为是独立的Actor。Actor和其他Actor通过发送异步消息通信。Actor模型的强大来自异步。也可以使用同步模式执行同步操作,但不建议使用同步消息,因为它们限制了系统的伸缩性。每个Actor有一个邮箱(Mailbox),用于存储所收到的消息。另外,每一个Actor维护自身单独的状态。一个Actor网络如图所示。
每个Actor是一个单一的线程,它不断地从其邮箱中拉取消息,并且连续不断地处理。对于已经处理过的消息的结果,Actor可以改变它自身的内部状态,或者发送一个新消息,或者孵化一个新的Actor。
Akka的通信
Akka有两种核心的异步通信方式:tell和ask。
1.tell方式
当使用tell方式时,表示仅仅使用异步方式给某个Actor发送消息,无须等待Actor的响应结果,并且也不会阻塞后续代码的运行,如:![]() 其中,第一个参数为消息,它可以是任何可序列化的数据或对象,第二个参数表示发送者,一般是另外一个Actor的引用,ActorRef.noSender()表示无发送者(实际上是一个叫作deadLetters的Actor)。
其中,第一个参数为消息,它可以是任何可序列化的数据或对象,第二个参数表示发送者,一般是另外一个Actor的引用,ActorRef.noSender()表示无发送者(实际上是一个叫作deadLetters的Actor)。
tell属于发了就完,什么都不管的类型。
2.ask方式
当需要从Actor获取响应结果时,可使用ask方法,ask方法会将返回结果包装在scala.concurrent.Future中,然后通过异步回调获取返回结果,调用方逻辑如代码所示。
ask发送完,还要在一定时间等待被发送方返回结果,如果指定超时时间(上面代码中的timeout字段)无返回结果,则抛出异常。(异步)
接收方必须通过getSender().tell(reply, getSelf()) 发送回应来为返回的 Future 填充数据。
ask 操作包括创建一个内部临时actor来处理回应,必须为这个内部actor指定一个超时期限,过了超时期限内部actor将被销毁以防止内存泄露。
netty
netty是基于java nio的
Java NIO (非阻塞 I/O) 是一种 I/O 模型,它允许应用程序在不阻塞线程的情况下与 I/O 设备(例如网络套接字)进行交互。N是non-blocking的意思。
NIO是注意几个关键词:Java NIO: Channels and Buffers(通道和缓冲区)、Non-blocking IO(非阻塞IO)、Selectors(选择器)。
具体可以参考:
【Flink】第三十篇:Netty 之 Java NIO-腾讯云开发者社区-腾讯云
netty是什么
Netty是一个NIO客户端-服务器框架。Netty支持快速、简单地开发网络应用程序,如协议服务器和客户机,大大简化了网络编程,如TCP和UDP套接字服务器。Netty经过精心设计,并积累了许多协议(如ftp、smtp、http)的实施经验,以及各种二进制基于文本的遗留协议。因此,Netty成功找到了一种方法,可以在不妥协的情况下实现轻松的开发、性能、稳定性和灵活性。

Netty是典型的Reactor模型结构,Reactor模型就是将消息放到一个队列中,通过异步线程池对其进行消费。
netty的基本工作流程
无论是服务器还是客户端都会关联一个channel(socket),channel上会绑定一个pipeline,pipeline绑定若干个handler,用来专门用来处理和业务有关的东西,handler有DownHandler和UpHandler两种,DownHandler用来处理发包,UpHandler用来处理收包,大致过程如下图所示。

flink中akka通信流程
actor是一个包含状态和行为的容器。
Akka在Flink中用于三个分布式技术组件之间的通信,他们是JobClient,JobManager,TaskManager。Akka在Flink中主要的作用是用来充当一个coordinator的角色。
它们之间的一些通信流程如下图所示:
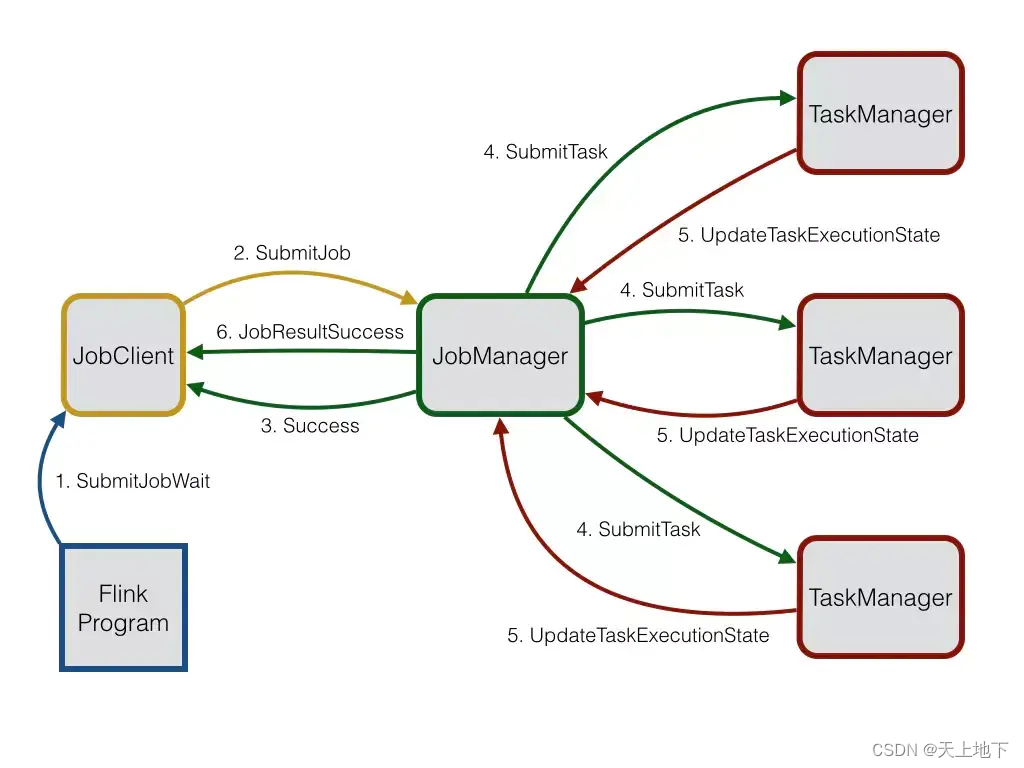
上图中三个使用Akka通信的分布式组件都具有自己的actor系统。
Flink 中的 Akka 通信遵循以下机制:
- **Actor 创建:**每个 Flink 组件(例如 JobManager、TaskManager)都创建自己的 ActorSystem。然后,它们创建 Actor 来处理特定任务。
- **消息发送:**Actor 使用 tell 方法向其他 Actor 发送消息。
- **消息处理:**接收 Actor 使用 receive 方法处理收到的消息。
- **消息路由:**Akka 使用路由器将消息路由到正确的 Actor。Flink 使用各种路由策略,例如随机路由、轮询路由和广播路由。
- **异常处理:**Akka 提供异常处理机制,以便在出现错误时通知 Actor。
flink中netty通信流程
详细流程可以参考:
Flink源码分析——Task数据交互之Netty通信 - 知乎
总结下基本流程就是:
1、flink数据的通信采用的netty框架,分为客户端和服务端,每个taskmanager即是客户端也是服务端,客户端用于向上游任务请求数据,服务端用于接收下游客户端请求,将数据发送给下游任务,数据处理的逻辑都是在ChannelHandler中完成
2、在初始化TaskManager的时候,就会初始化NettyServer和NettyClient
3、消费端任务线程从InputGate中获取数据,而InputGate会调用requestPartitions()来向上游节点发起数据请求(按分区来获取数据),InputGate中有很多RemoteInputChannel,每个RemoteInputChannel会创建partitionRequestClient,通过partitionRequestClient向服务端发请求
4、创建完partitionRequestClient之后,就会发起数据请求,首先创建一个请求实例PartitionRequest,包含了请求的是哪个ResultSubPartition,和当前的RemoteInputChannel初始Credit。Credit是信任消费凭证,简单来说就是消费者有多个credit,生产端就能给消费端发送多少个数据buffer(反压机制)
5、生产者(服务端)接收到客户端的PartitionRequest之后,会给这个请求创建一个reader,即CreditBasedSequenceNumberingViewReader,这个reader随后会创建一个ResultSubpartitionView,reader就是通过这个ResultSubpartitionView来从对应的ResultSubpartition里读取数据。生产者的每个ResultSubPartition都会对应一个下游任务的请求(每个RemoteInputChannel消费一个ResultSubPartition),同时都会有一个reader。
6、ResultSubpartitionView创建之后会立刻触发数据发送,触发PartitionRequestQueue.writeAndFlushNextMessageIfPossible()方法,简单来说数据的处理逻辑就是reader从ResultSubPartition中读取一个buffer,同时信任值credit减1;如果ResultSubPartition中还有可用的数据会继续入队被轮询读数据,如果reader中的credit信任值等于0了,也不能再消费了;最后会将buffer进行封装发送给消费者,同时还封装了ResultSubPartition中的积压量信息
7、消费者同样调用CreditBasedPartitionRequestClientHandler.channelRead()来处理接收到的数据,先拿到这个消息的所属的InputChannel,然后从InputChannel中获取一个buffer。将接收到的消息数据拷贝到buffer中,再将buffer添加到RemoteInputChannel的buffer数据列表中,同时将自己入队到InputGate中,以便可以让自己继续被InputGate所轮询消费。
8、消费端RemoteInputChannel判断生产端的数据积压量,决定要向LocalBufferPool申请多少个空闲buffer,同时新申请的buffer数要反馈给生产者,增加生产者的credit值,以便生产者可以继续往消费者发送数据。当RemoteInputChannel有新的空闲buffer加入的时候,都会增加credit值,反馈给生产者。最终调用CreditBasedPartitionRequestClientHandler.writeAndFlushNextMessageIfPossible()发送AddCredit消息给生产者,也即Netty的服务端
9、生产者(服务端)再接收到credit信任值后,会给对应的reader增加credit值,意味着可以继续往消费者发送credit个数量的buffer了。
10、在此之后,生产者、消费者之间将循环进行这个数据交互过程,生产者将数据发送给消费者,消费者反馈credit给生产者(消费者有多个credit,生产端就能给消费端发送多少个数据buffer--反压机制),使得数据可以进行持续的生产、消费。
spark中netty通信流程
一些概念

RpcEnv
RpcEnv 管理各个 RpcEndpoint 并将发送自 RpcEndpointRef 或远程节点的消息分发给对应的 RpcEndpoint。
RpcEndpoint
RPCEndpoint是一个通信实体,定义了如何处理消息(即,使用哪个函数来处理指定消息),在通过 name 向Dispatcher完成注册后,RpcEndpoint 就一直存放在 RpcEnv 中。Endpoint和EndpointRef以键值对的形式放在ConcurrentHashMap中。RpcEndpoint 的生命周期按顺序是 onStart,receive 及 onStop,receive 可以被同时调用,如果希望 receive 是线程安全的,可以使用 ThreadSafeRpcEndpoint。
RpcEndpoint提供了多个消息处理方法:
| 方法名 |
说明 |
| receive |
接收消息并处理,但不回复 |
| receiveAndReply |
接收消息处理后,并给客户端回复 |
| onError |
发生异常时,调用 |
| onConnected |
当客户端与当前节点连接上后调用 |
| onDisconnected |
当客户端与当前节点失去连接上后调用 |
| onNetworkError |
当网络连接发生错误进行处理 |
| onStart |
在 RpcEndpoint 处理消息前调用,可以在 RpcEndpoint 正式工作前做一些准备工作 |
| onStop |
在停止 RpcEndpoint 前调用,可以在 RpcEndpoint 结束前做一些收尾工作 |
RpcEndpointRef
RpcEndpointRef 是 RpcEnv 中的 RpcEndpoint 的引用,是一个序列化的实体以便于通过网络传送或保存以供之后使用。要向远端的一个RpcEndpoint发起请求,必须拿到RpcEndpoint的引用。
一个 RpcEndpointRef 有一个地址和名字。可以调用 RpcEndpointRef 的 send 方法发送异步的单向的消息给对应的 RpcEndpoint。RpcEndpointRef 指定了 ip 和 port,是一个类似 spark://host:port/name 这种的地址。
Inbox
一个本地端点对应一个收件箱,Inbox 里面有一个 InboxMessage 的链表,InboxMessage 有很多子类,可以是远程调用过来的 RpcMessage,可以是远程调用过来的 fire-and-forget 的单向消息 OneWayMessage,还可以是各种服务启动,链路建立断开等 Message,这些 Message 都会在 Inbox 内部的方法内做模式匹配,调用相应的 RpcEndpoint 的函数。
Outbox
一个远程端点对应一个发件箱,NettyRpcEnv 中包含一个 ConcurrentHashMap[RpcAddress, Outbox]。当消息放入 Outbox 后,紧接着将消息通过 TransportClient 发送出去。
EndPointData
Dispatcher进行消息分发,分发的就是EndpointData对象,封装了endpoint的name、Endpoint、EndpointRef、Inbox。
Dispatcher
消息分发器,负责将 RpcMessage 分发至对应的 RpcEndpoint。Dispatcher 中包含一个 MessageLoop,它读取 LinkedBlockingQueue 中的投递 RpcMessage,根据客户端指定的 Endpoint 标识,找到 Endpoint 的 Inbox,然后投递进去,由于是阻塞队列,当没有消息的时候自然阻塞,一旦有消息,就开始工作。Dispatcher 的 ThreadPool 负责消费这些 Message,由ThreadPool中的MessageLoop进行处理。
了解了这些概念,就可以看通信流程了:
本地消息通信
Endoint通信终端点调用NettyRpcEndpointRef的send和ask方法,向本地节点的RpcEndpoint发送消息,由于是在同一节点,所以直接调用Dispatcher的postLocalMessage或postOneWayMessage方法,将消息放入EndpointData内部的Inbox的message列表中。
远程消息通信
Endoint通信终端点通过NettyRpcEndpointRef的send方法和ask方法向远端节点的RpcEndpoint发送消息,首先将消息封装成OutboxMessage,然后放入Outbox的message列表中。(每个Outbox与RpcEndpoint是一一对应的)。
每个Outbox中会调用drainOutbox方法不断循环,从messages列表中取得OutboxMessage。Outbox中会使用内部的TransportClient向远端的NettyRpcEnv发送OutboxMessage。和远端的NettyRpcEnv的TransportServer建立了连接后,请求消息首先经过Netty管道的处理,然后经由NettyRpcHandler的处理,最后来自服务端NettyRpcServer的回复消息会触发NettyRpcHandler的receive方法,进而调用Dispatcher的postRemoteMessage或者postOneWayMessage方法。
远程消息通信过程如下图所示。

消息分发器Dispatcher把消息分发到每个endpoint并进行消息处理的流程如下图所示。

智能推荐
Ubuntu系统入门指南:基础操作和使用-程序员宅基地
文章浏览阅读2.1k次,点赞32次,收藏49次。本文的目的是为读者提供一个全面的Ubuntu系统入门指南,帮助他们了解Ubuntu系统的基础操作和使用方法。Ubuntu系统作为一种免费、开源、安全、稳定且易于使用的操作系统,越来越受到用户的青睐。然而,对于新手来说,掌握Ubuntu系统的操作和使用可能会有一定的困难。因此,本文的重要性在于向读者介绍Ubuntu系统的基本知识和技巧,帮助他们顺利开始使用Ubuntu系统,并最大限度地发挥其功能和优势。通过本文的阅读,读者将能够掌握Ubuntu系统的安装、基础操作、日常使用和高级功能,并能够解决常见问题。_ubuntu
MSSQL-最佳实践-行级别安全解决方案-程序员宅基地
文章浏览阅读158次。title: MSSQL-最佳实践-行级别安全解决方案author: 风移摘要在SQL Server安全系列专题月报分享中,我们已经分享了:如何使用对称密钥实现SQL Server列加密技术、使用非对称密钥加密方式实现SQL Server列加密、使用混合密钥实现SQL Server列加密技术和列加密技术带来的查询性能问题以及相应解决方案四篇文章。..._mssql security
Ardunio开发实例-敲击传感器_敲击传感器模块arduino-程序员宅基地
文章浏览阅读1k次。敲击传感器振动是自然界最普遍的现象之一,大至宇宙小至原子粒子,无不存在振动现象。在工程技术领域中振动现象比比皆是,但在很多情况下振动是有害的,例如:振动降低加工精度和光洁度,加剧结构件的疲劳和磨损,在车辆和航空领域中机体及结构件的振动不但会影响驾驶员的操作和舒适度,严重情况下还会引起机体、结构件的断裂甚至解体。敲击传感器是用于检测冲击力或者加速度的传感器 ,通常使用的是加上应力就会产生电荷的压电器件,也有采用别的材料和方法可以进行检测的传感器。本次实例使用的敲击传感器相对简单,如下图所示:1、硬件_敲击传感器模块arduino
机器学习——决策树(Decision Trees)_机器学习-决策树-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏11次。机器学习学习笔记——3_机器学习-决策树
基于STC12C5A60S2系列1T 8051单片机的带字库液晶显示器LCD12864数据传输并行模式显示常规字符应用_lcd2864字库-程序员宅基地
文章浏览阅读406次,点赞11次,收藏6次。LCD12864点阵型液晶显示器是一种具有4 位或8 位并行、2 线或3线串行多种接口方式,内部可含有或不含有国标一级、二级简体中文字库的点阵型液晶显示器。其中LCD12864点阵型液晶显示器中128表示128列,64表示64行,总共有128x64=8192个点。_lcd2864字库
杭电计算机组成实验6(六)MIPS汇编器与模拟器实验_计组 汇编器实验-程序员宅基地
文章浏览阅读3.2k次,点赞4次,收藏8次。实验内容1. 学习 MIPS指令系统,熟悉 MIPS指令格式及其汇编指令助记符,掌握机器指令编码方法2. 学习 MIPS汇编程序设计,学会使用 MIPS 汇编器将汇编语言程序翻译成二进制文件3. 了解使用 MIPS教学系统模拟器运行程序的方法解决方法下载 PCSpim 软件给大家按照书上的要求,在文本编辑器中输入汇编程序,然后装入PCSpim左侧内为指令地址,中间是十六进制的指令编码,右侧是相应的标准汇编指令,主要注意的是第二个程序,必须在裸机执行方式核心 结果展示:..._计组 汇编器实验
随便推点
QT:理想单薄透镜的参数计算_qt画单透镜-程序员宅基地
文章浏览阅读1.2k次,点赞6次,收藏24次。给定理想单薄透镜的像距和物距,计算出该透镜的像距、轴向放大率、横向放大率和角放大率直接上代码.pro#-------------------------------------------------## Project created by QtCreator 2021-12-10T13:24:32##-------------------------------------------------QT += core guigreaterThan(QT_MAJO_qt画单透镜
Visual Studio Code的安装教程(后期的如何安装插件、配置C语言的环境等看我之后的文章)_visual studio 怎么安装插件-程序员宅基地
文章浏览阅读1.1k次,点赞2次,收藏3次。我们来看Visual Studio Code如何下载和安装吧!Visual Studio Code是微软做的,但是它和Visual Studio没有半毛钱关系。Visual Studio Code是一个独立的编辑器,当然它有很好的功能,我们可以把它配置好来做编程的各种各样的事情。_visual studio 怎么安装插件
【HarmonyOS】HarmonyOS参考资料_harmonyos应用开发者高级认证考试入口-程序员宅基地
文章浏览阅读429次,点赞9次,收藏8次。【资料】【HarmonyOS】HarmonyOS参考资料_harmonyos应用开发者高级认证考试入口
unturned服务器怎么自定义,《Unturned》机房服务器开服方法图文教程-程序员宅基地
文章浏览阅读1.1k次。《Unturned》机房服务器开服方法图文教程2014-08-05 09:39:57来源:贴吧编辑:评论(0)《Unturned》游戏中有些玩家想自己开服,之前给大家介绍了各种开服方法,今天给大家带来更直观的开服方法,一起来看看吧。多种开服方法:点击进入1.在服务器下载安装steam.(登录时建立个新的号来登录)2.用steam下载unturned.3.先运行一次,出现“oops”等崩溃错误 点掉..._unturned3.0怎么开服
RSA加密算法-程序员宅基地
文章浏览阅读84次。公钥加密,私钥解密,称为RSA加密算法。私钥加密,公钥解密,称为RSA签名算法。
C语言指针详解(函数指针)_c函数指针-程序员宅基地
文章浏览阅读1.3k次,点赞20次,收藏27次。函数指针说白了也是一个指针,指针中所保存的地址中的内容是一个函数,同之前说过的数组指针相似,函数指针的定义便是返回类型 (* 指针名) (函数参数) //例如: int (*pa) (intx,iny)同数组指针一样,当定义函数指针的时候,* 需要和指针名打括号相结合,( )的优先级高于 * ,不打括号编译器自动会将 指针名 与( )相结合,如 int * pa (int x,int y) ,这样的话便是一个名为pa的函数,函数参数为 int x,int y,函数的返回类型时 int *_c函数指针