DL框架之Keras:深度学习框架Keras框架的简介、安装(Python库)、相关概念、Keras模型使用、使用方法之详细攻略_keras——keras简介、安装及backend-程序员宅基地
技术标签: Keras/Caffe python 深度学习 keras
DL框架之Keras:深度学习框架Keras框架的简介、安装(Python库)、相关概念、Keras模型使用、使用方法之详细攻略
目录
3、Keras深度学习框架的注意事项(自动下载存放路径等)、使用方法之详细攻略
相关文章
DL框架之Keras:Python库之Keras库的简介、安装、使用方法详细攻略
keras-yolo3:python库之keras-yolo3的简介、安装、使用方法详细攻略
Keras的简介

Keras是TensorFlow官方的高层API。Keras是一个高层神经网络API,并对TensorFlow等有较好的优化。,Keras由纯Python编写而成并基Tensorflow、Theano以及CNTK后端,也就是Keras基于什么东西来做运算。Keras 为支持快速实验而生,能够把你的idea迅速转换为结果。
1、Keras的特点
- tensorflow.keras(tf.keras) module
- Part of core TensorFlow since v1.4
- Full Keras API
- 针对TF更好的优化
- 与TF特别功能更好的整合,Estimator API、Eager execution
2、Keras四大特性
- 1、用户友好:Keras是为人类而非机器设计的API。用户的使用体验始终是我们考虑的首要和中心内容。Keras遵循减少认知困难的最佳实践:Keras提供一致而简洁的API, 能够极大减少一般应用下用户的工作量,同时,Keras提供清晰和具有实践意义的bug反馈。
- 2、模块性:模型可理解为一个层的序列或数据的运算图,完全可配置的模块可以用最少的代价自由组合在一起。具体而言,网络层、损失函数、优化器、初始化策略、激活函数、正则化方法都是独立的模块,你可以使用它们来构建自己的模型。
- 3、易扩展性:添加新模块超级容易,只需要仿照现有的模块编写新的类或函数即可。创建新模块的便利性使得Keras更适合于先进的研究工作。
- 4、与Python协作:Keras没有单独的模型配置文件类型(作为对比,caffe有),模型由python代码描述,使其更紧凑和更易debug,并提供了扩展的便利性。
3、Keras的用户体验
(1)、Keras是专为人而非机器设计的API
- 它把用户体验放在首要和中心位置。
- Keras遵循减少认知困难的最佳实践:它提供一致且简单的API,将常见用例所需的用户操作数量降至最低,并且在用户错误时提供清晰和可操作的反馈。
(2)、Keras易于学习且易于使用
- 作为Keras用户,可以更高效地工作,让你比竞争对手更快地尝试更多创意和帮助你赢得机器学习竞赛。
(3)、这种易用性不是以降低灵活性为代价
- Keras与低级深度学习语言(特别是TensorFlow)集成,能够实现可以用基本语言构建的任何东西。特别是,作为tf.keras,Keras API与TensorFlow工作流程无缝集成。
4、如果你有如下需求,请选择Keras
- 简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性)
- 支持CNN和RNN,或二者的结合
- 无缝CPU和GPU切换。
5、Keras支持多后端和多平台
(1)、支持多种语言:Develop in Python, R On Unix, Windows, OSX
(2)、支持多个后端:Keras与TensorFlow&Theano

TensorFlow和theano以及Keras都是深度学习框架,TensorFlow和theano比较灵活,也比较难学,它们其实就是一个微分器 Keras其实就是TensorFlow和Keras的接口(Keras作为前端,TensorFlow或theano作为后端),它也很灵活,且比较容易学。可以把keras看作为tensorflow封装后的一个API。Keras 是一个用于快速构建深度学习原型的高级库。我们在实践中发现,它是数据科学家应用深度学习的好帮手。Keras 目前支持两种后端框架:TensorFlow 与 Theano,而且 Keras 再过不久就会成为 TensorFlow 的默认 API。
Run the same code with…
- -TensorFlow
- -CNTK
- -Theano
- -MXNet
- -PlaidML
(3)、支持多运算平台:CPU, NVIDIA GPU, AMD GPU, TPU
Keras: 基于 Python 的深度学习库
Keras中文文档
tensorflow.org/guide/keras
Keras的安装
在安装keras之前,要先安装tensorflow
推荐文章:DL框架之Tensorflow:深度学习框架Tensorflow的简介、安装、使用方法之详细攻略
pip install keras
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple keras
python -m pip install keras
哈哈,大功告成!继续学习去啦!
pip install --upgrade keras
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple keras
190827更新到2.2.5

190827再次还原到2.2.4

230317

相关文章
Py之keras-resnet:keras-resnet的简介、安装、使用方法之详细攻略
Keras的使用方法
0、三种API方式
The Sequential Model (序列模型)、The functional API (函数式API)、Model subclassing(模型子类化)
from keras.models import Model
from keras.callbacks import ModelCheckpoint
from keras.layers import Conv2D, MaxPool2D, Flatten, Dropout, Dense, Input
from keras.optimizers import Adam
from keras.backend.tensorflow_backend import set_session
from keras.utils.vis_utils import model_to_dot
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
np.random.seed(5)
config = tf.ConfigProto()
config.gpu_options.allow_growth=True
set_session(tf.Session(config=config))1、The Sequential Model 序列模型
-非常简单
-仅适用于单输入,单输出,顺序的层堆叠
-适用于70%以上的用例
| Sequential 序列模型如所示 | |
| 可以简单地使用.add() 来堆叠模型 |  |
| 在完成了模型的构建后, 可以使用.compile() 来配置学习过程: |  |
| 如果需要,还可以进一步地配置优化器: | |
| 批量地在训练数据上进行迭代: | # x_train 和y_train 是Numpy 数组--就像在Scikit-Learn API 中一样 或者,可以手动地将批次的数据提供给模型: |
| 一行代码就能评估模型性能: | |
| 对新的数据生成预测 |
1、快速开始序贯(Sequential)模型
序贯模型是多个网络层的线性堆叠,也就是“一条路走到黑”。
(1)、可以通过向Sequential模型传递一个layer的list来构造该模型:
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([ Dense(32, units=784), Activation('relu'), Dense(10), Activation('softmax'), ])
(2)、也可以通过.add()方法一个个的将layer加入模型中:
model = Sequential() model.add(Dense(32, input_shape=(784,)))
model.add(Activation('relu'))
#引入Sequential,Dense,Activation
from keras.models import Sequential
from keras.layers import Dense, Activation
#向layer添加list方式
model = Sequential([Dense(32, input_dim=784),Activation('relu'),Dense(10),Activation('softmax'),])
#通过.add()方式
model = Sequential()
model.add(Dense(32, input_dim=784))
model.add(Activation('relu'))2、The functional API 函数式API
-象玩乐高积木
-多输入,多输出,任意静态图拓扑
-适用于95%的用例
Keras 函数式API 是定义复杂模型(如多输出模型、有向无环图,或具有共享层的模型)的方法。
| 例一:全连接网络 |  |
3、Model subclassing 模型子类化
-最大的灵活性
-更大的可能错误面
(1)、通过对tf.keras.Model 进行子类化并定义你自己的前向传播来构建完全可自定义的模型。在__init__ 方法中创建层并将它们设置为类实例的属性。在call 方法中定义前向传播。
(2)、在启用Eager Execution 时,模型子类化特别有用,因为可以命令式地编写前向传播。
(3)、以下示例展示了使用自定义前向传播进行子类化的tf.keras.Model
class MyModel(tf.keras.Model):
def __init__(self, num_classes=10):
super(MyModel, self).__init__(name='my_model')
self.num_classes = num_classes
# Define your layers here.
self.dense_1 = layers.Dense(32, activation='relu')
self.dense_2 = layers.Dense(num_classes, activation='sigmoid')
def call(self, inputs):
# Define your forward pass here,
# using layers you previously defined (in `__init__`).
x = self.dense_1(inputs)
return self.dense_2(x)
def compute_output_shape(self, input_shape):
# You need to override this function if you want to use the subclassed model
# as part of a functional-style model.# Otherwise, this method is optional.
shape = tf.TensorShape(input_shape).as_list()
shape[-1] = self.num_classes
return tf.TensorShape(shape)
实例化新模型类
model = MyModel(num_classes=10) # The compile step specifies the training configuration.
model.compile(optimizer=tf.train.RMSPropOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# Trains for 5 epochs.
model.fit(data, labels, batch_size=32, epochs=5)
其他概念
1、shape
(1)、指定输入数据的shape
模型需要知道输入数据的shape,因此,Sequential的第一层需要接受一个关于输入数据shape的参数,后面的各个层则可以自动的推导出中间数据的shape,因此不需要为每个层都指定这个参数。
(2)、关于张量shape 更多详细内容参考这个博客https://blog.csdn.net/u013378306/article/details/56281549
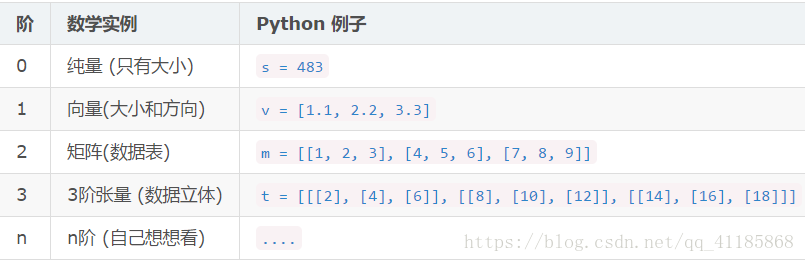
在Keras和Tensorflow中,数据是以张量的形式表示的,张量的形状就是shape。TensorFlow用张量这种数据结构来表示所有的数据.你可以把一个张量想象成一个n维的数组或列表.一个张量有一个静态类型和动态类型的维数.张量可以在图中的节点之间流通即Flow。
你可以认为一个二阶张量就是我们平常所说的矩阵,一阶张量可以认为是一个向量.对于一个二阶张量你可以用语句t[i, j]来访问其中的任何元素.而对于三阶张量你可以用't[i, j, k]'来访问其中的任何元素.
(1)input_shape就是指输入张量的shape。例如 input_dim=784,说明输入是一个784维的向量,这相当于一个一阶的张量,它的shape就是(784,)
2、回调
1、回调是传递给模型的对象,用于在训练期间自定义该模型并扩展其行为。你可以编写自定义回调,也可以使用包含以下方法的内置tf.keras.callbacks:
tf.keras.callbacks.ModelCheckpoint '定期保存模型的检查点。'
tf.keras.callbacks.LearningRateScheduler '动态更改学习速率。'
tf.keras.callbacks.EarlyStopping '在验证效果不再改进时中断训练。'
tf.keras.callbacks.TensorBoard '使用TensorBoard 监控模型的行为。'2、要使用tf.keras.callbacks.Callback,请将其传递给模型的fit 方法:
callbacks = [
# Interrupt training if `val_loss` stops improving for over 2 epochs
tf.keras.callbacks.EarlyStopping(patience=2, monitor='val_loss'),
# Write TensorBoard logs to `./logs` directory
tf.keras.callbacks.TensorBoard(log_dir='./logs')
]
model.fit(data, labels, batch_size=32, epochs=5, callbacks=callbacks,
validation_data=(val_data, val_labels))3、保存和恢复
(1)仅限权重:使用tf.keras.Model.save_weights 保存并加载模型的权重
model = tf.keras.Sequential([layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')])
model.compile(optimizer=tf.train.AdamOptimizer(0.001),
loss='categorical_crossentropy',metrics=['accuracy'])
'默认情况下,会以TensorFlow 检查点文件格式保存模型的权重'
# Save weights to a TensorFlow Checkpoint file
model.save_weights('./weights/my_model')
# Restore the model's state,# this requires a model with the same architecture.
model.load_weights('./weights/my_model')
'权重也可以另存为KerasHDF5 格式(Keras多后端实现的默认格式)'
# Save weights to a HDF5
filemodel.save_weights('my_model.h5', save_format='h5')
# Restore the model's statemodel.
load_weights('my_model.h5')(2)、仅限配置:可以保存模型的配置,此操作会对模型架构(不含任何权重)进行序列化。即使没有定义原始模型的代码,保存的配置也可以重新创建并初始化相同的模型。Keras 支持JSON 和YAML 序列化格式:
# Serialize a model to JSON format
json_string = model.to_json()
json_string
import json
import pprint
pprint.pprint(json.loads(json_string))
'从json重新创建模型'
fresh_model = tf.keras.models.model_from_json(json_string)(3)整个模型:整个模型可以保存到一个文件中,其中包含权重值、模型配置乃至优化器配置。这样,您就可以对模型设置检查点并稍后从完全相同的状态继续训练,而无需访问原始代码。
# Create a trivial model
model = tf.keras.Sequential([layers.Dense(10, activation='softmax', input_shape=(32,)),
layers.Dense(10, activation='softmax')])
model.compile(optimizer='rmsprop',loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(data, labels, batch_size=32, epochs=5)
# Save entire model to a HDF5 file
model.save('my_model.h5')
# Recreate the exact same model, including weights and optimizer.
model = tf.keras.models.load_model('my_model.h5')4、动态图机制:Eager Execution
不同于TensorFlow的静态机制。
- Eager Execution 是一种命令式编程环境,可立即评估操作。此环境对于Keras 并不是必需的,但是受tf.keras 的支持,并且可用于检查程序和调试。
- 所有tf.keras 模型构建API 都与Eager Execution 兼容。虽然可以使用Sequential 和函数式API,但Eager Execution 对模型子类化和构建自定义层特别有用。
- 与通过组合现有层来创建模型的API 不同,函数式API 要求你编写前向传播代码。
Keras的中的模型使用
1、查找使用方法
from keras.models import Sequential
model = Sequential()
help(model.compile)
(1)、model.compile()函数,用来配置训练模型参数,可以指定你设想的随机梯度下降中的网络的损失函数、优化方式等参数(2)、model.summary()函数,Prints a string summary of the network.
(3)、model.fit_generator()函数,Fits the model on data generated batch-by-batch by a Python generator.The generator is run in parallel to the model, for efficiency.For instance, this allows you to do real-time data augmentation on images on CPU in parallel to training your model on GPU.
(4)、K.placeholder() #用于得到传递进来的真实的训练样本
2、Keras的 6 种预训练模型
目前可知,Keras 已经将这 6 种预训练模型集成到了库中: VGG16、VGG19、ResNet50、Inception v3、Xception、MobileNet。VGG 网络以及从 2012 年以来的 AlexNet 都遵循现在的基本卷积网络的原型布局:一系列卷积层、最大池化层和激活层,最后还有一些全连接的分类层。MobileNet 本质上是为移动应用优化后的 Xception 架构的流线型(streamline)版本。
3、Keras深度学习框架的注意事项(自动下载存放路径等)、使用方法之详细攻略
智能推荐
Linux应用 环境变量的增删查改_linux 删除环境变量-程序员宅基地
文章浏览阅读1k次,点赞34次,收藏28次。本文阐述了Linux中环境变量的一些基本概念,列出了控制台操作常用命令和应用编程常用的接口,并编写示例进行简单测试_linux 删除环境变量
Three.js/WebGL系统课程3D可视化(郭隆邦老师的)_three.js可视化系统课程webgl 郭隆邦-程序员宅基地
文章浏览阅读929次,点赞4次,收藏7次。webgl threejs 课程Three.js/WebGL系统课程3D可视化(郭隆邦老师)_three.js可视化系统课程webgl 郭隆邦
如何在DOS命令窗口从C盘进入D盘?_dos怎么从c盘到d盘-程序员宅基地
文章浏览阅读3.6k次。点击开始,打开运行输入cmd,进入DOS窗口输入D:即可进入D盘_dos怎么从c盘到d盘
思岚激光雷达+cartographer建图_思岚a1与cartographer-程序员宅基地
文章浏览阅读4.3k次,点赞6次,收藏71次。思岚+cartographer_思岚a1与cartographer
开源埋点工具分析比较_开源埋点系统-程序员宅基地
文章浏览阅读1w次。开源埋点工具分析查找和比较_开源埋点系统
vite+vue3 2-程序员宅基地
文章浏览阅读63次。答:选择To check syntax, find problems, and enforce code style(检查语法、发现问题并强制执行代码风格)1.在vue3中,规则vue/name-property--casing已经被vue/component-definition-name-casing代替,在使用前者会出错。a).安装postcss和postcss-preset-env插件:npm install postcss postcss-preset-env -D。(你想遵循哪一种风格指南?
随便推点
使用uni-app自动注册全局组件_unaipp components 组件 自动注册-程序员宅基地
文章浏览阅读2.1k次。全局共用组件为经常使用,所以自动化注册是个不错的选择;方式1:webpack的 require.context方式此方式适用于浏览器端,如需兼容看下面的方式2// /*// **全局注册组件// ** 放在components/global文件夹下// ** 仅适用于h5端, 微信端-移步到pages.json的easycom配置, 以App开头命名name// */const requireComponent = require.context( './global', tr_unaipp components 组件 自动注册
区块链技术是什么?解析其基本原理及应用_10.区块链技术的基本原理是什么?它有哪些应用场景?-程序员宅基地
文章浏览阅读548次,点赞7次,收藏8次。区块链技术起源于加密货币比特币,如今区块链技术非常流行,你对于这项技术有多少了解?本文我们为大家来讲诉关于这项技术的一些知识,包括其基本原理和在生活中的应用。_10.区块链技术的基本原理是什么?它有哪些应用场景?
Java 发送邮件,本地可以,部署后发送失败-程序员宅基地
文章浏览阅读3.4k次,点赞5次,收藏3次。基于 SpringBoot 的邮件发送功能,只解决问题,具体发送代码不做赘述。基本配置# 这个配置在本地测试时没问题spring.mail.host=smtp.qq.comspring.mail.username=1006209986@qq.comspring.mail.password=这里是授权码(一般不是邮箱密码)spring.mail.default-encoding=UTF-8本地测试没问题,部署到阿里云服务器后发不出去。【没有报错信息】# 之所以不报错,是因为默认的超时时间无限
C语言中的关系运算符_xxdyx-程序员宅基地
文章浏览阅读1.1k次。大于:> 判断左边的数是否大于右边的数,结果为1则为真,结果为0则为假小于:< 判断左边的数是否小于右边的数,结果为1则为真,结果为0则为假大于等于:>= 判断左边的数是否大于或等于右边的数小于等于:>= 判断左边的数是否小于或等于右边的数不等于:!= 判断左边的数是否不等于右边的数等于:== 判断左边的数是否等于右边的数..._xxdyx
九齐MCU单片机 NY8A051H 微控制器芯片方案开发烧录芯片编带SOP8-程序员宅基地
文章浏览阅读245次,点赞8次,收藏4次。本文详细介绍了NY8BM072A微控制器芯片方案的开发过程,包括芯片特点、开发环境搭建、芯片烧录以及编带SOP16封装等步骤。本文将详细介绍NY8BM072A微控制器芯片方案的开发过程,包括烧录芯片和编带SOP16封装等步骤。在选择烧录工具时,需要确保其与NY8BM072A芯片兼容,并具备稳定的烧录性能。4. 封装过程监控:在封装过程中,需要实时监控芯片的位置、引脚状态以及封装材料的质量,确保封装质量符合要求。(3)设置烧录参数:根据芯片规格书,设置正确的烧录参数,如起始地址、结束地址等。
爽文被搬上小程序短剧,用十万成本撬动千万生意-程序员宅基地
文章浏览阅读1.1k次,点赞36次,收藏16次。和传统长视频相比,小程序短剧不注水,在最短的时间内,完成更多的戏剧矛盾冲突和反转,也更容易抓住观众的好奇心。小程序短剧的主打就是短、快、剧情爽,人们对于视频内容要求的情绪价值,小程序短剧能很好的贴合需求。通过以上商业盈利模式,短剧小程序可以实现多方面的收入来源,包括广告收入、付费会员收入和虚拟商品销售收入,从而为开发者带来可观的经济效益。如果不想组建小程序开发团队,想定制化开发小程序,有个性化功能需要满足,建议采取外包开发的方式,选择专业的开发服务商,列出自己的开发需求,交给专业的团队去开发维护。