Elasticsearch教程(9) Mapping 字段类型 keyword text date numeric_es mappings什么时候会把字段解析成text-程序员宅基地
技术标签: date mapping Elasticsearch elasticsearch 字段类型 keyword
Mapping 字段类型
前言
- 我们在用MySQL时,如果表结构定义不好,后期开发会不断踩坑。
- 用ES也是如此,虽然ES有mapping动态映射,但是它自动生成的不一定是我们期望的。学好ES的mapping很重要。在学习ES查询和聚合之前,应该先打好mapping的基础,学习顺序不能变。这和学习SQL一样,先学习数据类型有int,char,varchar等,然后再学习group by,having等。
核心字段类型
- ES支持的字段类型很多,但我们工作中常用的也就那些核心字段。
- 一开始学习ES时,掌握好常用的类型,不必要精通每一种,如果工作中遇到了需要用到特殊类型再去研究。
- 学习一门技术要先广度后深度,不能陷入”只见树木,不见森林“。
1 keyword
- keyword是关键词类型,ES把keyword类型的值当作词根存在倒排索引中,不进行分词。
- keyword适合存结构化数据,比如name,age,性别,手机号,status(数据状态),tags(标签),HttpCode(404,200,500)等。
- 字段常用来精确查询,过滤,排序,聚合时,应设为keyword,而不是数值型。
- 最长支持32766个UTF-8类型的字符,但放入倒排索引时,只截取前一段字符串,长度由ignore_above参数决定。
1.1 举例说明keyword
| 举例:数据状态字段 |
#如果一个字段经常用来放查询条件里过滤数据和聚合统计,
#最好设为keyword,而不是数值型
GET pigg/_search
{
"query": {
"term": {
"status": 2
}
}
}
1.2 ignore_above是什么?
首先随意往ES插一条数据:
put my_index/_doc/1
{
"name": "李星云"
}
查看ES自动生成的mapping,name是text类型,其下还有子类型keyword,且"ignore_above" : 256
GET /my_index/_mapping
name定义如下:
"properties" : {
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
对于keyword类型, 可设置ignore_above限定字符长度。超过 ignore_above 的字符会被存储,但不会被倒排索引。比如ignore_above=4,”abc“,”abcd“,”abcde“都能存进ES,但是不能根据”abcde“检索到数据。
【1】创建一个keyword类型的字段,ignore_above=4
PUT test_index
{
"mappings": {
"_doc": {
"properties": {
"message": {
"type": "keyword",
"ignore_above": 4
}
}
}
}
}
【2】向索引插入3条数据:
PUT /test_index/_doc/1
{
"message": "abc"
}
PUT /test_index/_doc/2
{
"message": "abcd"
}
PUT /test_index/_doc/3
{
"message": "abcde"
}
此时ES倒排索引是:
| 词项 | 文档ID |
|---|---|
| abc | 1 |
| abcd | 2 |
【3】根据message进行terms聚合:
GET /test_index/_search
{
"size": 0,
"aggs": {
"term_message": {
"terms": {
"field": "message",
"size": 10
}
}
}
}
返回结果:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 1.0,
"hits" : [
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"message" : "abcd"
}
},
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"message" : "abc"
}
},
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"message" : "abcde"
}
}
]
},
"aggregations" : {
"term_message" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [#注意这分组里没有”abcde“
{
"key" : "abc",
"doc_count" : 1
},
{
"key" : "abcd",
"doc_count" : 1
}
]
}
}
}
【4】根据”abcde“进行term精确查询,结果为空
GET /test_index/_search
{
"query": {
"term": {
"message": "abcde"
}
}
}
然后结果:
"hits" : {
"total" : 0,
"max_score" : null,
"hits" : [ ]
}
通过上面结果能知道”abcde“已经存入ES,也可以搜索出来,但是不存在词项”abcde“,不能根据”abcde“作为词项进行检索。
对于已存在的keyword字段,其ignore_above子属性可以修改,但只对新数据有效。
2 text
- text文本类型,如果要对字符串进行分词分析,可以设置为text。
- ES自带了很多分词器,如果是中文,可以给ES安装ik中文分词插件。
- 关于分词器属性的配置可以参考ES官网分析的章节。
2.1 举例说明text类型分词
在上面1.1.2节,新增了my_index索引,其中name是text类型。
分析在name上”I am a coder“这个短语是怎么被分词的。
GET /my_index/_analyze
{
"field": "name",
"text": "I am a coder"
}
结果如下图,这短语分成4个词项,其中大写”I“还转换为小写”i“。
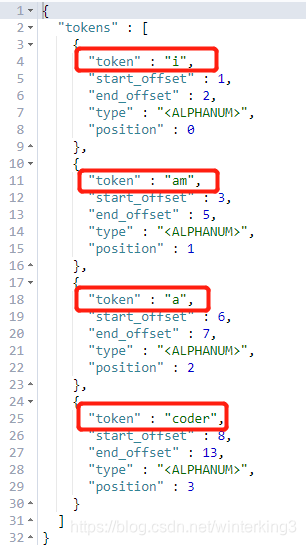
字符串”I am a coder“,ES不会把这个完整的字符串保存起来,它保存的形式如下:
| 词 | 假设文档ID=1 |
|---|---|
| i | 1 |
| am | 1 |
| a | 1 |
| coder | 1 |
所以根据”I am a coder“这完整字符串是查询不到数据的。
3 Boolean类型
| 判断 | ES接受的值 |
|---|---|
| 真 | true, “true” |
| 假 | false, “false”,""(空字符串) |
具体代码案例参考Elasticsearch笔记(二十三) 详解mapping之boolean
4 日期类型
JSON没有date数据类型,所以ES里日期可有以下数据:
- 日期格式的字符串,如"2015-01-01"或"2015/01/01 12:10:30"
- 从开始纪元(1970-01-01 00:00:00 UTC)开始的毫秒数-长整型
- 从开始纪元(1970-01-01 00:00:00 UTC)开始的秒数-整型
上面的UTC(Universal Time Coordinated) 叫做世界统一时间,中国大陆和 UTC 的时差是 + 8 ,也就是 UTC+8。在ES内部,时间以毫秒数的UTC存储。
date的格式可以被指定的,如果没有特殊指定,默认格式是"strict_date_optional_time||epoch_millis"
这段话可以理解为格式为strict_date_optional_time或者epoch_millis
4.1 什么是epoch_millis?
epoch_millis就是从开始纪元(1970-01-01 00:00:00 UTC)开始的毫秒数-长整型。
4.2 什么是strict_date_optional_time?
strict_date_optional_time是date_optional_time的严格级别,这个严格指的是年份、月份、天必须分别以4位、2位、2位表示,不足两位的话第一位需用0补齐。
常见的格式有如下:
- yyyy
- yyyyMM
- yyyyMMdd
- yyyyMMddHHmmss
- yyyy-MM
- yyyy-MM-dd
- yyyy-MM-ddTHH:mm:ss
- yyyy-MM-ddTHH:mm:ss.SSS
- yyyy-MM-ddTHH:mm:ss.SSSZ
工作常见到是"yyyy-MM-dd HH:mm:ss",但是ES是不支持这格式的,需要在dd后面加个T,这个是固定格式。上面最后一个里大写的"Z"表示时区。
下面做测试:
#新增一个索引,设置birthday是date格式。
PUT /test_date_index
{
"mappings": {
"_doc":{
"properties":{
"birthday":{
"type": "date"
}
}
}
}
}
#插入yyyy-MM-dd HH:mm:ss格式
PUT /test_date_index/_doc/3
{
"birthday": "2020-03-01 16:29:41"
}
结果报错:
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Invalid format: \"2020-03-01 16:29:41\" is malformed at \" 16:29:41\""
}
#插入 yyyy-MM-ddTHH:mm:ss格式,ES返回成功
PUT /test_date_index/_doc/4
{
"birthday": "2020-03-01T16:29:41"
}
4.3 你就是想用yyyy-MM-dd HH:mm:ss?
date类型,还支持一个参数format,它让我们可以自己定制化日期格式。
比如format配置了“格式A||格式B||格式C”,插入一个值后,会从左往右匹配,直到有一个格式匹配上。
#先删除索引
DELETE test_date_index
#重建索引
PUT /test_date_index
{
"mappings": {
"_doc":{
"properties":{
"birthday":{
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
}
#2020/03/01 17:44:09的毫秒级时间戳
PUT /test_date_index/_doc/1
{
"birthday": 1583055849000
}
PUT /test_date_index/_doc/2
{
"birthday": "2020-03-01 16:29:41"
}
PUT /test_date_index/_doc/3
{
"birthday": "2020-02-29"
}
#上面3条语句都可以保存成功
5 数字:Numeric
为了提高性能和减少存储空间,选择一个满足存放你数据的类型就可以,没有必要选择过长的类型。比如各地人口数量,一般用integer存储足够了,没有必要使用long类型。
| 类型 | 说明 |
|---|---|
| byte | 8位,-128 ~ 127 |
| short | 16位,-32768 ~ 32767 |
| integer | 32位,-231 ~ 231-1 |
| long | 64位,-263 ~ 263-1 |
| float | 单精度、32位、符合IEEE 754标准的浮点数 |
| double | 双精度、64位、符合IEEE 754标准的浮点数 |
| half_float | 16位半精度IEEE 754浮点类型 |
| scaled_float | 缩放类型的的浮点数 |
5.1 创建一个新的索引
PUT pigg_test_num
{
"mappings": {
"properties": {
"num_of_byte": {
"type": "byte"
},
"num_of_short": {
"type": "short"
},
"num_of_integer": {
"type": "integer"
},
"num_of_long": {
"type": "long"
},
"num_of_float": {
"type": "float"
},
"num_of_double": {
"type": "double"
}
}
}
}
5.2 插入正确的数据
PUT pigg_test_num/_doc/1
{
"num_of_byte": 127,
"num_of_short": 32767,
"num_of_integer": 2147483647,
"num_of_long": 9223372036854775807,
"num_of_float": 0.33333,
"num_of_double": 11111111111111.11111111111111111
}
查看文档的数据
GET pigg_test_num/_search
返回:
{
"hits":[
{
"_index":"pigg_test_num",
"_type":"_doc",
"_id":"1",
"_score":1,
"_source":{
"num_of_byte":127,
"num_of_short":32767,
"num_of_integer":2147483647,
"num_of_long":9223372036854776000,
"num_of_float":0.33333,
"num_of_double":11111111111111.111
}
}
]
}
5.3 插入越界的数据
short的最大值是32767
PUT pigg_test_num/_doc/2
{
"num_of_byte": 127,
"num_of_short": 32768
}
返回报错
"reason" : "Numeric value (32768) out of range of Java short..."
5.4 给整数赋值浮点数
给long类型赋值浮点数, 虽然能够存储成功,但是已经丢失了精度,所以工作中不能这么用
PUT pigg_test_num/_doc/1
{
"num_of_long": 9223372036854775807.0001
}
返回
"_source" : {
"num_of_long" : 9.223372036854776E18
}
5.5 给整数赋值浮点数的字符串
给long类型赋值浮点数, 虽然能够存储成功, 但是存的就是字符串,而不是数字.
PUT pigg_test_num/_doc/1
{
"num_of_long": "9223372036854775807.0001"
}
返回
"_source" : {
"num_of_long" : "9223372036854775807.0001"
}
下面验证存的是字符串而不是数字
#期望给long的值加上2
POST pigg_test_num/_update/1
{
"script": {
"source": "ctx._source.num_of_long += 2",
"lang": "painless"
}
}
# 返回值却是给字符串拼接加上字符"2"
"_source" : {
"num_of_long" : "9223372036854775807.00012"
}
总结: 综合上面错误的实验, 可以知道工作中还是得传正确格式和范围的数字.
6 二进制类型:binary
ES能接受以Base64编码的二进制值,binary字段是不会被分析存储和检索的。因为它的值就是一巨长的乱码,对它分析毫无意义, 它只是被原模原样的存储。
工作中可能用binary存储图像,但情况也不多,用ES存图像不是很好的选择。
Base64编码简单说下,如下图:对单词"Man",它Base64编码是TWFu。

智能推荐
AndroidStudio无代码高亮解决办法_android studio 高亮-程序员宅基地
文章浏览阅读2.8k次。AndroidStudio 升级到 4.2.2 版本后,没有代码高亮了,很蛋疼。解决办法是:点开上方的 File,先勾选 Power Save Mode 再取消就可以了。_android studio 高亮
swift4.0 valueForUndefinedKey:]: this class is not key value coding-compliant for the key unity.'_forundefinedkey swift4-程序员宅基地
文章浏览阅读1k次。使用swift4.0整合Unity出现[ valueForUndefinedKey:]: this class is not key value coding-compliant for the key unity.'在对应属性前加@objc 即可。或者调回swift3.2版本_forundefinedkey swift4
Spring Security2的COOKIE的保存时间设置_springsecurity 设置cookie失效时间-程序员宅基地
文章浏览阅读1.3k次。http auto-config="true" access-denied-page="/common/403.htm"> intercept-url pattern="/login.**" access="IS_AUTHENTICATED_ANONYMOUSLY"/> form-login login-page="/login.jsp" defau_springsecurity 设置cookie失效时间
view滑动冲突解决实战篇2(外部拦截法)_viewpage2外部拦截事件-程序员宅基地
文章浏览阅读1.1k次。继上篇内部拦截法需求还是跟上篇一样。只不过这次用外部拦截法来解决;只要在父容器添加如下代码就可以解决了滑动冲突,很简单,套模板就行 // 分别记录上次滑动的坐标(onInterceptTouchEvent) private int mLastXIntercept = 0; private int mLastYIntercept = 0; @Override public bo_viewpage2外部拦截事件
汇编 堆栈 变量存储 指针_汇编语言栈指针-程序员宅基地
文章浏览阅读2.5k次,点赞7次,收藏9次。本文章系作者原创,未经许可,不得转载。汇编 堆栈 变量存储 指针先说栈的概念,栈其实也是一种。。。。。先说内存的概念吧。。。。。额 先说计算机吧,简单来说的话,可以把计算机理解成由CPU,内存,硬盘组成,而CPU内部又包括一种叫做内部寄存器的东西,包括 数据寄存器: AX,BX,CX,DX; 段寄存器: CS,DS,ES,SS; 指针与变址寄存器SP,BP,SI,DI; ..._汇编语言栈指针
架构师之路:从码农到架构师你差了哪些_web架构师-程序员宅基地
文章浏览阅读1w次,点赞14次,收藏56次。转载自 架构师之路:从码农到架构师你差了哪些 Web应用,最常见的研发语言是Java和PHP。 后端服务,最常见的研发语言是Java和C/C++。 大数据,最常见的研发语言是Java和Python。 可以说,Java是现阶段中国互联网公司中,覆盖度最广的研发语言,掌握了Java技术体系,不管在成熟的大公司,快速发展的公司,还是创业阶段的公司,都能有立足之地。有..._web架构师
随便推点
超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了_爬虫python入门-程序员宅基地
文章浏览阅读7.3k次,点赞6次,收藏36次。超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了_爬虫python入门
python怎么输出logistic回归系数_python - Logistic回归scikit学习系数与统计模型的系数 - SO中文参考 - www.soinside.com...-程序员宅基地
文章浏览阅读1.2k次。您的代码存在一些问题。首先,您在此处显示的两个模型是not等效的:尽管您将scikit-learn LogisticRegression设置为fit_intercept=True(这是默认设置),但您并没有这样做statsmodels一;来自statsmodels docs:默认情况下不包括拦截器,用户应添加。参见statsmodels.tools.add_constant。另一个问题是,尽管您处..._sm fit(method
VS2017、VS2019配置SFML_vsllfqm-程序员宅基地
文章浏览阅读518次。一、sfml官网下载32位的版本 一样的设置,64位的版本我没有成功,用不了。二、三、四以下这些内容拷贝过去:sfml-graphics-d.libsfml-window-d.libsfml-system-d.libsfml-audio-d.lib..._vsllfqm
vc——类似与beyondcompare工具的文本比较算法源代码_byoned compare 字符串比较算法-程序员宅基地
文章浏览阅读2.7k次。由于工作需要,要做一个类似bc2的文本比较工具,用红色字体标明不同的地方,研究了半天,自己写了一个简易版的。文本比较的规则是1.先比较文本的行数,2.再比较对应行的字符串的长度3.再比较每一个字符串是否相同。具体代码如下:其中m_basestr和m_mergestr里面存放是待比较的字符串int basecount=m_basestr.GetLength(); int mergec_byoned compare 字符串比较算法
aetna java_pom.xml-程序员宅基地
文章浏览阅读79次。xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/maven-v4_0_0.xsd">org.apacheapache174.0.0org.apache.atlasapache-atlas3.0.0-SNAPSHOTMetadata Management and Data Govern..._atlas.pom
生成随机数_<math.h>随机数-程序员宅基地
文章浏览阅读1.5k次。C语言中有可以产生随机数据的函数,需要添加 stdlib. h头文件与time.h头文件。首先在main函数开头加上“ srand(unsigned)time(NULL));",这个语句将生成随机数的种子(不懂也没关系,只要记住这个语句,并且知道 srand是初始化随机种子用的即可)。然后,在需要使用随机数的地方使用 rand()函数。下面是一段生成十个随机数的代码:程序代码:#incl..._随机数