OpenAI的人工智能语音识别模型Whisper详解及使用_ai虚拟老师语音识别-程序员宅基地
技术标签: 音视频处理 深度学习 pytorch whisper AI数字人技术 语音识别
1 whisper介绍
拥有ChatGPT语言模型的OpenAI公司,开源了 Whisper 自动语音识别系统,OpenAI 强调 Whisper 的语音识别能力已达到人类水准。
Whisper是一个通用的语音识别模型,它使用了大量的多语言和多任务的监督数据来训练,能够在英语语音识别上达到接近人类水平的鲁棒性和准确性。Whisper还可以进行多语言语音识别、语音翻译和语言识别等任务。Whisper的架构是一个简单的端到端方法,采用了编码器-解码器的Transformer模型,将输入的音频转换为对应的文本序列,并根据特殊的标记来指定不同的任务。
Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。OpenAI 认为使用这样一个庞大而多样的数据集,可以提高对口音、背景噪音和技术术语的识别能力。除了可以用于语音识别,Whisper 还能实现多种语言的转录,以及将这些语言翻译成英语。OpenAI 开放模型和推理代码,希望开发者可以将 Whisper 作为建立有用的应用程序和进一步研究语音处理技术的基础。
代码地址:代码地址
2 whisper模型
2.1 使用数据集
Whisper模型是在68万小时标记音频数据的数据集上训练的,其中包括11.7万小时96种不同语言的演讲和12.5万小时从”任意语言“到英语的翻译数据。该模型利用了互联网生成的文本,这些文本是由其他自动语音识别系统(ASR)生成而不是人类创建的。该数据集还包括一个在VoxLingua107上训练的语言检测器,这是从YouTube视频中提取的短语音片段的集合,并根据视频标题和描述的语言进行标记,并带有额外的步骤来去除误报。
2.2 模型
主要采用的结构是编码器-解码器结构。
重采样:16000 Hz
特征提取方法:使用25毫秒的窗口和10毫秒的步幅计算80通道的log Mel谱图表示。
特征归一化:输入在全局内缩放到-1到1之间,并且在预训练数据集上具有近似为零的平均值。
编码器/解码器:该模型的编码器和解码器采用Transformers。
- 编码器的过程
编码器首先使用一个包含两个卷积层(滤波器宽度为3)的词干处理输入表示,使用GELU激活函数。
第二个卷积层的步幅为 2。
然后将正弦位置嵌入添加到词干的输出中,然后应用编码器 Transformer 块。
Transformers使用预激活残差块,编码器的输出使用归一化层进行归一化。
- 模型结构
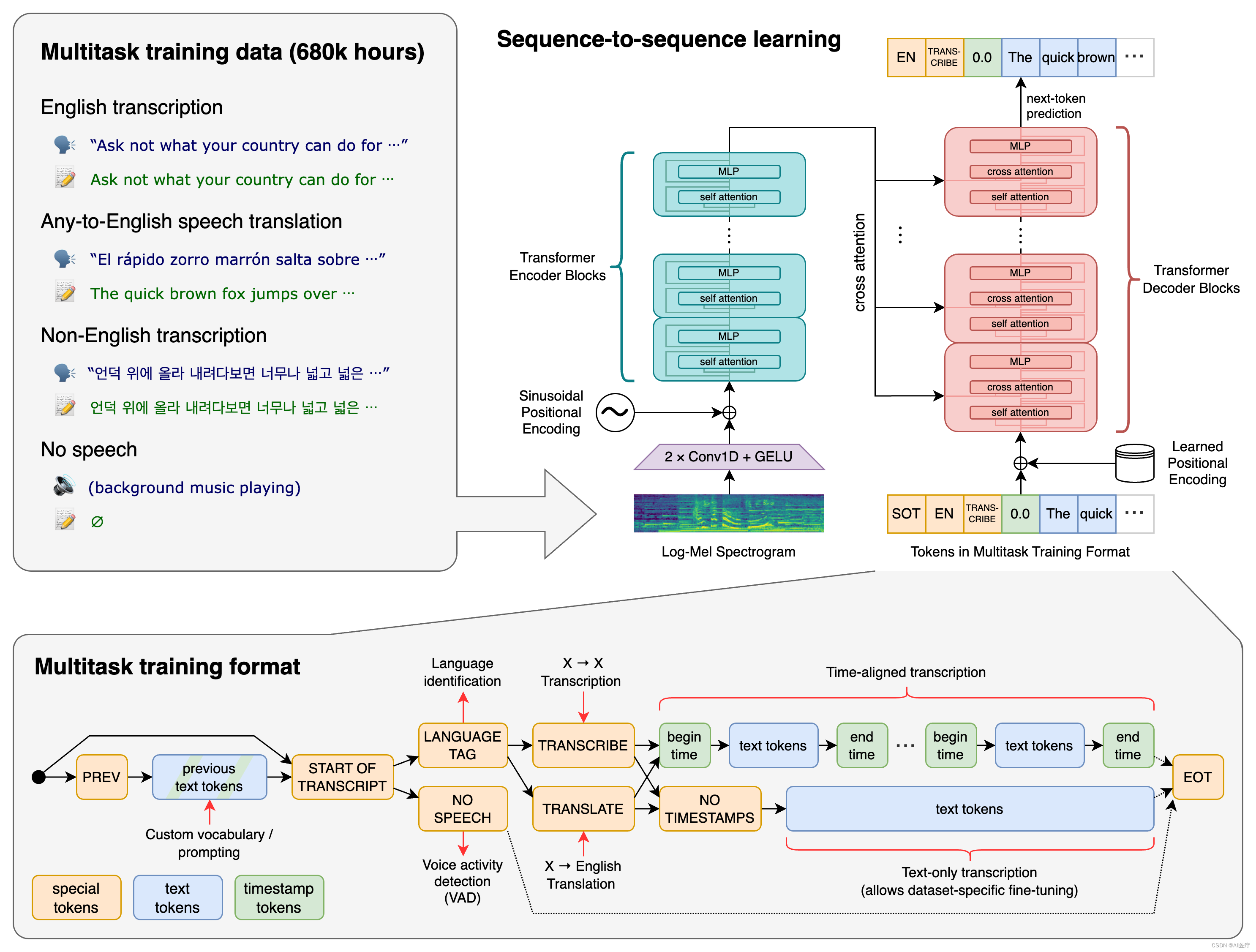
- 解码的过程
在解码器中,使用了学习位置嵌入和绑定输入输出标记表示。
编码器和解码器具有相同的宽度和数量的Transformers块。
2.3 训练
输入的音频被分割成 30 秒的小段、转换为 log-Mel 频谱图,然后传递到编码器。解码器经过训练以预测相应的文字说明,并与特殊的标记进行混合,这些标记指导单一模型执行诸如语言识别、短语级别的时间戳、多语言语音转录和语音翻译等任务。
相比目前市面上的其他现有方法,它们通常使用较小的、更紧密配对的「音频 - 文本」训练数据集,或使用广泛但无监督的音频预训练集。因为 Whisper 是在一个大型和多样化的数据集上训练的,而没有针对任何特定的数据集进行微调,虽然它没有击败专攻 LibriSpeech 性能的模型(著名的语音识别基准测试),然而在许多不同的数据集上测量 Whisper 的 Zero-shot(不需要对新数据集重新训练,就能得到很好的结果)性能时,研究人员发现它比那些模型要稳健得多,犯的错误要少 50%。
为了改进模型的缩放属性,它在不同的输入大小上进行了训练。
- 通过 FP16、动态损失缩放,并采用数据并行来训练模型。
- 使用AdamW和梯度范数裁剪,在对前 2048 次更新进行预热后,线性学习率衰减为零。
- 使用 256 个批大小,并训练模型进行 220次更新,这相当于对数据集进行两到三次前向传递。
由于模型只训练了几个轮次,过拟合不是一个重要问题,并且没有使用数据增强或正则化技术。这反而可以依靠大型数据集内的多样性来促进泛化和鲁棒性。
Whisper 在之前使用过的数据集上展示了良好的准确性,并且已经针对其他最先进的模型进行了测试。
2.4 优点
-
Whisper 已经在真实数据以及其他模型上使用的数据以及弱监督下进行了训练。
-
模型的准确性针对人类听众进行了测试并评估其性能。
-
它能够检测清音区域并应用 NLP 技术在转录本中正确进行标点符号的输入。
-
模型是可扩展的,允许从音频信号中提取转录本,而无需将视频分成块或批次,从而降低了漏音的风险。
-
模型在各种数据集上取得了更高的准确率。
Whisper在不同数据集上的对比结果,相比wav2vec取得了目前最低的词错误率
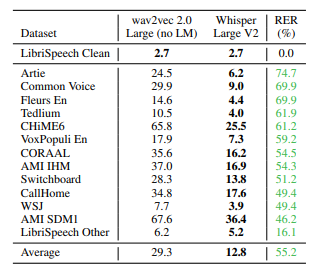
模型没有在timit数据集上进行测试,所以为了检查它的单词错误率,我们将在这里演示如何使用Whisper来自行验证timit数据集,也就是说使用Whisper来搭建我们自己的语音识别应用。
2.5 whisper的多种尺寸模型
whisper有五种模型尺寸,提供速度和准确性的平衡,其中English-only模型提供了四种选择。下面是可用模型的名称、大致内存需求和相对速度。

模型的官方下载地址:
"tiny.en": "https://openaipublic.azureedge.net/main/whisper/models/d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03/tiny.en.pt",
"tiny": "https://openaipublic.azureedge.net/main/whisper/models/65147644a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9/tiny.pt",
"base.en": "https://openaipublic.azureedge.net/main/whisper/models/25a8566e1d0c1e2231d1c762132cd20e0f96a85d16145c3a00adf5d1ac670ead/base.en.pt",
"base": "https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt",
"small.en": "https://openaipublic.azureedge.net/main/whisper/models/f953ad0fd29cacd07d5a9eda5624af0f6bcf2258be67c92b79389873d91e0872/small.en.pt",
"small": "https://openaipublic.azureedge.net/main/whisper/models/9ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794/small.pt",
"medium.en": "https://openaipublic.azureedge.net/main/whisper/models/d7440d1dc186f76616474e0ff0b3b6b879abc9d1a4926b7adfa41db2d497ab4f/medium.en.pt",
"medium": "https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt",
"large-v1": "https://openaipublic.azureedge.net/main/whisper/models/e4b87e7e0bf463eb8e6956e646f1e277e901512310def2c24bf0e11bd3c28e9a/large-v1.pt",
"large-v2": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",
"large": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",3 whisper环境构建及运行
3.1 conda环境安装
参见:annoconda安装
3.2 whisper环境构建
conda create -n whisper python==3.9
conda activate whisper
pip install openai-whisper
conda install ffmpeg
pip install setuptools-rust3.3 whisper命令行使用
whisper /opt/000001.wav --model base输出内容如下:
[00:00.000 --> 00:02.560] 人工智能识别系统。执行命令时,会自动进行模型下载,自动下载模型存储的路径如下:
~/.cache/whisper也可以通过命令行制定本地模型运行:
Whisper /opt/000001.wav --model base --model_dir /opt/models --language Chinese支持的文件格式:m4a、mp3、mp4、mpeg、mpga、wav、webm
3.4 whisper在代码中使用
import whisper
model = whisper.load_model("base")
result = model.transcribe("/opt/000001.wav")
print(result["text"])智能推荐
尚硅谷_谷粒学苑-微服务+全栈在线教育实战项目之旅_基于微服务的在线教育平台尚硅谷-程序员宅基地
文章浏览阅读2.7k次,点赞3次,收藏11次。SpringBoot+Maven+MabatisPlusmaven在新建springboot项目引入RELEASE版本出错maven在新建springboot项目引入RELEASE版本出错maven详解maven就是通过pom.xml中的配置,就能够从仓库获取到想要的jar包。仓库分为:本地仓库、第三方仓库(私服)、中央仓库springframework.boot:spring-boot-starter-parent:2.2.1.RELEASE’ not found若出现jar包下载不了只有两_基于微服务的在线教育平台尚硅谷
java 实现 数据库备份_java数据备份-程序员宅基地
文章浏览阅读1k次。数据库备份的方法第一种:使用mysqldump结合exec函数进行数据库备份操作。第二种:使用php+mysql+header函数进行数据库备份和下载操作。下面 java 实现数据库备份的方法就是第一种首先我们得知道一些mysqldump的数据库备份语句备份一个数据库格式:mysqldump -h主机名 -P端口 -u用户名 -p密码 --database 数据库名 ..._java数据备份
window10_ffmpeg调试环境搭建-编译64位_win10如何使用mingw64编译ffmpeg-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏14次。window10_ffmpeg调试环境搭建_win10如何使用mingw64编译ffmpeg
《考试脑科学》_考试脑科学pdf百度网盘下载-程序员宅基地
文章浏览阅读6.3k次,点赞9次,收藏14次。给大家推荐《考试脑科学》这本书。作者介绍:池谷裕二,日本东京大学药学系研究科教授,脑科学研究者。1970年生于日本静冈县,1998年取得日本东京大学药学博士学位,2002年起担任美国哥伦比亚大学客座研究员。专业为神经科学与药理学,研究领域为人脑海马体与大脑皮质层的可塑性。现为东京大学药学研究所教授,同时担任日本脑信息通信融合研究中心研究主任,日本药理学会学术评议员、ERATO人脑与AI融合项目负责人。2008年获得日本文部大臣表彰青年科学家奖,2013年获得日本学士院学术奖励奖。这本书作者用非常通俗易懂_考试脑科学pdf百度网盘下载
今天给大家介绍一下华为智选手机与华为手机的区别_华为智选手机和华为手机的区别-程序员宅基地
文章浏览阅读1.4k次。其中,成都鼎桥通信技术有限公司是一家专业从事移动通讯终端产品研发和生产的高科技企业,其发布的TD Tech M40也是华为智选手机系列中的重要代表之一。华为智选手机是由华为品牌方与其他公司合作推出的手机产品,虽然其机身上没有“华为”标识,但是其品质和技术水平都是由华为来保证的。总之,华为智选手机是由华为品牌方和其他公司合作推出的手机产品,虽然外观上没有“华为”标识,但其品质和技术水平都是由华为来保证的。华为智选手机采用了多种处理器品牌,以满足不同用户的需求,同时也可以享受到华为全国联保的服务。_华为智选手机和华为手机的区别
c++求n个数中的最大值_n个数中最大的那个数在哪里?输出其位置,若有多个最大数则都要输出。-程序员宅基地
文章浏览阅读7.6k次,点赞6次,收藏17次。目录题目描述输入输出代码打擂法数组排序任意输入n个整数,把它们的最大值求出来.输入只有一行,包括一个整数n(1_n个数中最大的那个数在哪里?输出其位置,若有多个最大数则都要输出。
随便推点
Linux常用命令_ls-lmore-程序员宅基地
文章浏览阅读4.8k次,点赞17次,收藏51次。Linux的命令有几百个,对程序员来说,常用的并不多,考虑各位是初学者,先学习本章节前15个命令就可以了,其它的命令以后用到的时候再学习。1、开机 物理机服务器,按下电源开关,就像windows开机一样。 在VMware中点击“开启此虚拟机”。2、登录 启动完成后,输入用户名和密码,一般情况下,不要用root用户..._ls-lmore
MySQL基础命令_mysql -u user-程序员宅基地
文章浏览阅读4.1k次。1.登录MYSQL系统命令打开DOS命令框shengfen,以管理员的身份运行命令1:mysql -u usernae -p password命令2:mysql -u username -p password -h 需要连接的mysql主机名(localhost本地主机名)或是mysql的ip地址(默认为:127.0.0.1)-P 端口号(默认:3306端口)使用其中任意一个就OK,输入命令后DOS命令框得到mysql>就说明已经进入了mysql系统2. 查看mysql当中的._mysql -u user
LVS+Keepalived使用总结_this is the redundant configuration for lvs + keep-程序员宅基地
文章浏览阅读484次。一、lvs简介和推荐阅读的资料二、lvs和keepalived的安装三、LVS VS/DR模式搭建四、LVS VS/TUN模式搭建五、LVS VS/NAT模式搭建六、keepalived多种real server健康检测实例七、lvs持久性工作原理和配置八、lvs数据监控九、lvs+keepalived故障排除一、LVS简介和推荐阅读的资料 学习LVS+Keepalived必须阅读的三个文档。1、 《Keepalived权威指南》下载见http://..._this is the redundant configuration for lvs + keepalived server itself
Android面试官,面试时总喜欢挖基础坑,整理了26道面试题牢固你基础!(3)-程序员宅基地
文章浏览阅读795次,点赞20次,收藏15次。AIDL是使用bind机制来工作。java原生参数Stringparcelablelist & map 元素 需要支持AIDL其实Android开发的知识点就那么多,面试问来问去还是那么点东西。所以面试没有其他的诀窍,只看你对这些知识点准备的充分程度。so,出去面试时先看看自己复习到了哪个阶段就好。下图是我进阶学习所积累的历年腾讯、头条、阿里、美团、字节跳动等公司2019-2021年的高频面试题,博主还把这些技术点整理成了视频和PDF(实际上比预期多花了不少精力),包含知识脉络 + 诸多细节。
机器学习-数学基础02补充_李孟_新浪博客-程序员宅基地
文章浏览阅读248次。承接:数据基础02
短沟道效应 & 窄宽度效应 short channel effects & narrow width effects-程序员宅基地
文章浏览阅读2.8w次,点赞14次,收藏88次。文章目录1. 概念:Narrow Width Effect: 窄宽度效应Short Channel effects:短沟道效应阈值电压 (Threshold voltage)2. 阈值电压与沟道长和沟道宽的关系:Narrow channel 窄沟的分析Short channel 短沟的分析1. 概念:Narrow Width Effect: 窄宽度效应在CMOS器件工艺中,器件的阈值电压Vth 随着沟道宽度的变窄而增大,即窄宽度效应;目前,由于浅沟道隔离工艺的应用,器件的阈值电压 Vth 随着沟道宽度_短沟道效应