Pytorch学习 for hw3(2)Logisitic Regression_不归一化容易发散-程序员宅基地
技术标签: 机器学习 pytorch Hong _YiLi
文章目录
逻辑回归是由概率公式推导产生的,常用来做分类任务,拿手写数字辨识1-10为例:通过计算max{ P ( x = 0 ) , P ( x = 1 ) , . . . , P ( x = 9 ) P(x=0),P(x=1),...,P(x=9) P(x=0),P(x=1),...,P(x=9)},找出最大的概率值即为该x对应的类别。
1、Logisitic Regression
(1)前言
介绍一种下载数据集的方法,但是本次案例未使用到。
在安装pytorch时,有个torchvison工具包可以提供一些比较流行的数据集如MNISIT Dataset(手写数字数据),CIFAR-10(32╳32像素的像图片),但是需要在网上下载,下载方法如下:
import torchvision
train_set = torchvision.datasets.MNIST(root='D:/py文件/Hong YiLee/homework3/dataset/mnist', train=True, download=True)
test_set = torchvision.datasets.MNIST(root='D:/py文件/Hong YiLee/homework3/dataset/mnist', train=False, download=True)
root:若未下载过则标明下载地址,已经下载过则标明数据所在位置
train=True:表示提取的是training data,=False表示提取的是testing data
download=True:表示将在往网上下载,=False表示从本机提取
运行结果如下,就是速度有点慢(开了VPN也慢)

由于是分类问题所以,本次实例和上次的略有区别:现有三个输入x,对应两个分类y=0和y=1,求输入为4时,输出y为多少。
| x | y |
|---|---|
| 1.0 | 0 |
| 2.0 | 0 |
| 3.0 | 1 |
| 4.0 | ? |
所以,进而将问题简化为二分类问题即求P(y=0)、P(y=1),且P(y=1)=1-P(y=0),若P(y=0)>0.5那么y=0。由于P(y=0)可能接近0.5,那么在这种情况下分类器对于该x的类别是不确定的,应该输出“不确定”。
(2)知识点介绍:
可以将二分类问题简化为输出为[0,1]之间的回归问题。那么我们只需要将的线性回归的输出映射到[0,1]即可,而sigmiod函数恰好满足:定义域为(-∞,+∞),值域为(0,1)。当输出y>0.5则被归为1,小于0.5则被归为0。损失函数选用由概率推导出来的cross entropy(交叉熵),简称BCE(Binary Cross Entropy),最后要求和取平均值(对loss求导数的时候1/N会影响lr的大小,加上则不用将lr调的过大)。

torch.nn.BCELoss的参数详解点击链接
torch.nn.Functional的模块包含很多函数,其中有sigmoid函数,我使用的pytorch1.7.1版本已经弃用这种方法,可直接使用torch.sigmoid()
(3)完整代码:
(和Linear Regression差不多)
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
class LogisticRegressionModel(torch.nn.Module):
# 初始化
def __init__(self):
# 初始化从torch.nn.Module继承的属性
super(LogisticRegressionModel, self).__init__()
# 设置实例属性self.linear
self.linear = torch.nn.Linear(1, 1)
# 定义实例方法,添加输入x
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
criterion = torch.nn.BCELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for i in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
输出如下:
能看出随迭代次数的增加loss值在减小,最后一次的loss值为1.0836951732635498。
0 2.484407901763916
1 2.4654228687286377
2 2.44744610786438
3 2.4304330348968506
4 2.4143383502960205
5 2.399118423461914
测试对x=4的y的分类,结果y_pred =0.8407>0.5 所以分类正确
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
# y_pred = tensor([[0.8407]])
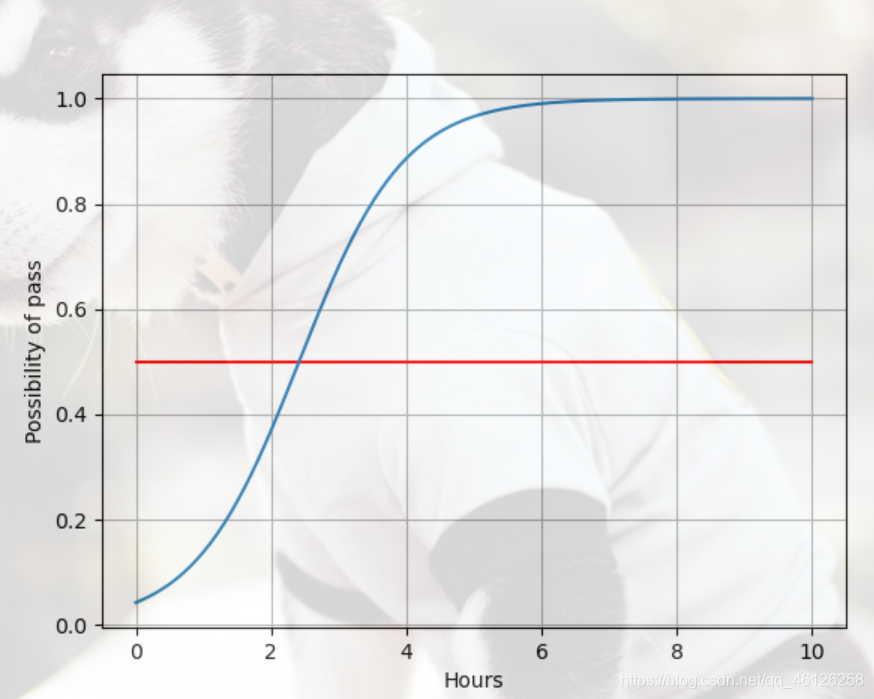
(4)查看y(是否通过考试)对x(每日的学习时间)的函数
(实际上并不是函数,是在取多个点之后的预测值绘制的图像)
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 10, 200) # 取1-10之间等间距的200个点,并组成一个列表
x_t = torch.Tensor(x).view((200, 1)) # 将1行的列表转为200行1列的列向量
y_t = model(x_t) # 输入x,调用logistic model
y = y_t.data.numpy() # 将y_data转化为numpy数据才能进行画图
plt.plot(x, y)
plt.plot([0, 10], [0.5, 0.5], c='r') # 画出分界线
plt.xlabel('Hours')
plt.ylabel('Possibility of pass')
plt.grid() # 画出背景网格线
plt.show() # 显示图
由于一使用plt.plot就出现下面的错误
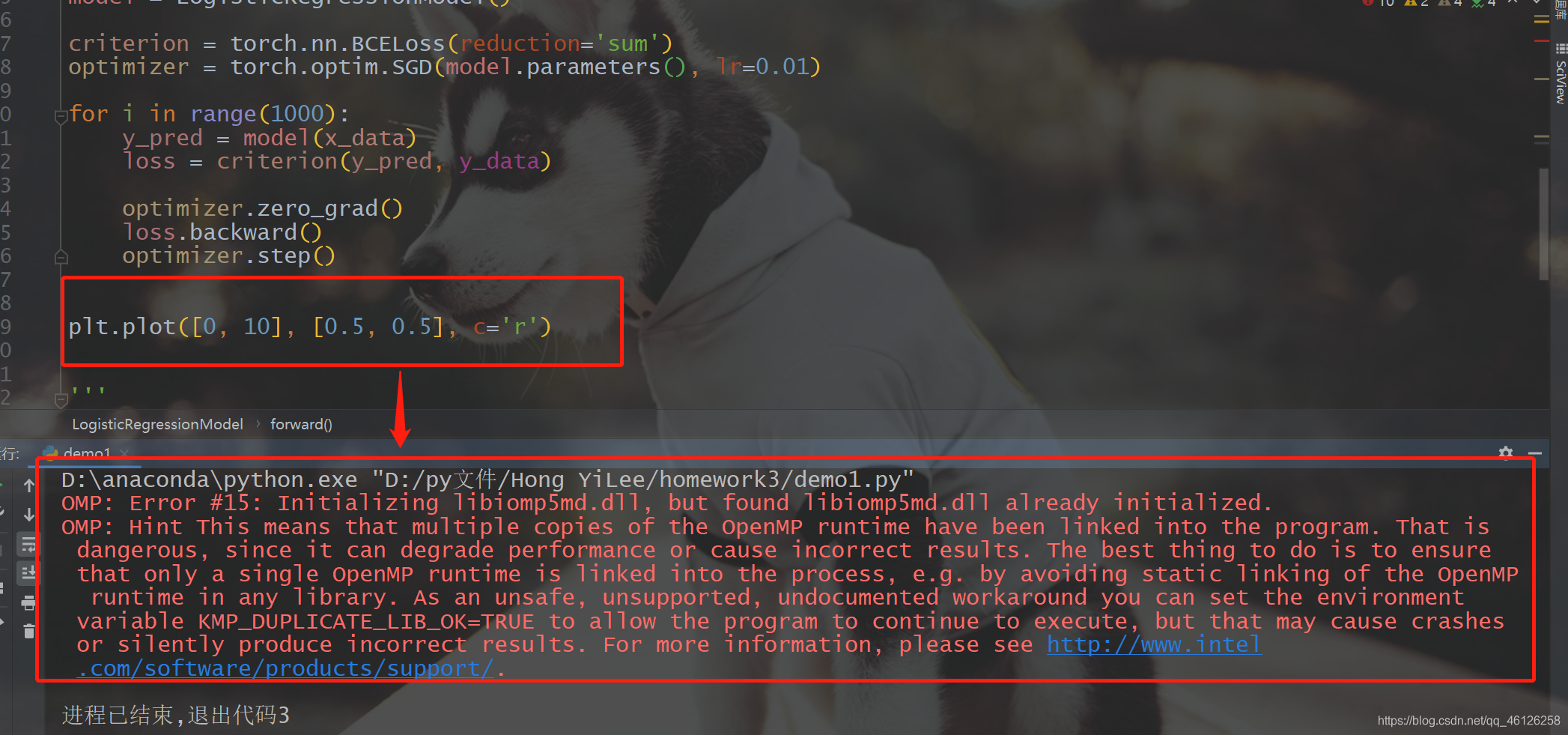
所以添加了一句,问题就解决了
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
结果如下,可以看到当学习时间为两个小时多的时候就会使possibility达到0.5,也就是y的取值为1,自然当x=4时y的取值也为1.
2、多层神经网络的连接
一层的时候运算过程如下:

可以将单个函数的运算拼成矩阵相乘,进而能够使用GPU加速运算过程。torch.nn.Linear(8,1)表示输入x有8列特征,输出y有1列。

当有三层的时候,可以将矩阵乘法看成维度转换的函数,只需要改变torch.nn.Linear()的参数就可以实现两层神经网络的连接单元数如下:

(1)二分类
在二分类中我们用到糖尿病的数据集(diabetes),通过8个特征辨别其是否患有糖尿病,患病输出y=1,否则y=0。
一、数据集的准备
下载链接:https://pan.baidu.com/s/1udhg5-pvS6UsQlpawmd8-w
提取码: itm0
打开文件如下

开始分离x、y
import numpy as np
xy = np.loadtxt('E:\\自制笔记\\课外\\PyTorch深度学习实践\\diabetes.csv.gz', delimiter=',', dtype=np.float32)
x = torch.from_numpy(xy[:, :-1]) # 取所有行的前8列,并转化为tensor
y = torch.from_numpy(xy[:, [-1]]) # 取所有行的的最后一列
print(x.shape, y.shape)
二、根据继承的模块定义model类
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__() # 初始化从Module继承的方法
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activation = torch.nn.Sigmoid()
def forward(self, x):
x = self.activation(self.linear1(x))
x = self.activation(self.linear2(x))
x = self.activation(self.linear3(x))
return x
model = Model()
三、设置loss和optimizer
由于size_average已经被弃用,所以使用reduction='mean’代替来求取平均值。
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
四、迭代更新
for epoch in range(100):
y_pred = model(x)
loss = criterion(y_pred, y)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
输出结果:
0 0.7159094214439392
1 0.7150604128837585
2 0.7142216563224792
3 0.7133930325508118
4 0.7125746011734009
5 0.7117661237716675
最后的loss值为 0.6668325662612915,当迭代次数达到1000次时,loss值为0.6445940732955933,并趋于稳定。
五、完整代码:
import torch
import numpy as np
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__() # 初始化从Module继承的方法
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activation = torch.nn.Sigmoid()
def forward(self, x):
x = self.activation(self.linear1(x))
x = self.activation(self.linear2(x))
x = self.activation(self.linear3(x))
return x
model = Model()
xy = np.loadtxt('E:\\自制笔记\\课外\\PyTorch深度学习实践\\diabetes.csv.gz', delimiter=',', dtype=np.float32)
x = torch.from_numpy(xy[:, :-1]) # 取所有行的前8列,并转化为tensor
y = torch.from_numpy(xy[:, [-1]]) # 取所有行的的最后一列
print(x.shape, y.shape)
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(100):
y_pred = model(x)
loss = criterion(y_pred, y)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
(2)回归问题
下面的案例是根据sklearn的diabetes数据集来做的回归问题。已知影响糖尿病的10列特征,和对应的target,查看随训练的变化loss的变化。
一、数据集准备:
如果安装了sklearn的话,在anaconda文件夹下能找到下图的路径,里面有自带的数据集,如我的位置是D:\anaconda\Lib\site-packages\sklearn\datasets\data
查看输入x: 打开之后发现WPS和excel并不能将每一列分割(只有两列间为" , "数据才能被分割,这里的是空格所以不能被分割为单独的列)

对应的y如下:
其中最小的为25,最大的为346 ,所以先对y进行归一化处理。不进行归一化结果会发散,loss值会很大。
import torch
import numpy as np
np.random.seed(0) #当我们设置相同的seed,每次生成的随机数相同
print()
# 按照sklearn中包的位置将数据读取出来
x = np.loadtxt('D:\\anaconda\\Lib\site-packages\\sklearn\\datasets\\data\\diabetes_data.csv.gz', delimiter=' ',
dtype=np.float32)
y = np.loadtxt('D:\\anaconda\\Lib\site-packages\\sklearn\\datasets\\data\\diabetes_target.csv.gz', delimiter=' ',
dtype=np.float32)
y = y.reshape(-1, 1) #转为一列
#归一化处理
mean_y = np.mean(y, axis = 0)
std_y = np.std(y, axis = 0)
for i in range(len(y)):
if std_y[0] != 0:
y[i][0] = (y[i][0] - mean_y[0]) / std_y[0]
#创建两个tensor
x = torch.from_numpy(x)
y = torch.from_numpy(y)
# 将数据的行数打乱
def _shuffle(X, Y):
# This function shuffles two equal-length list/array, X and Y, together.
randomize = np.arange(len(X))
np.random.shuffle(randomize)
return (X[randomize], Y[randomize])
x, y = _shuffle(x, y)
二、根据继承的模块定义model类
与二分类类似,但是由于y的输出不再是单个的类别(0、1),所以最后一层不能使用激活函数限制他的值域。
class Model(torch.nn.Module):
# 初始化,并定义激活函数
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(10, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activation = torch.nn.Sigmoid()
# 最后一层不要添加激活函数,否则最后的值域会被限制
def forward(self, x):
x = self.activation(self.linear1(x))
x = self.activation(self.linear2(x))
x = self.linear3(x)
return x
model = Model()
三、设置loss和optimizer
criterion = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
四、迭代更新
for i in range(100):
y_pred = model(x)
loss = criterion(y_pred, y)
print(i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
结果如下:
0 1.1163854598999023
1 1.0310304164886475
2 1.0081417560577393
3 1.001995325088501
4 1.0003454685211182
随迭代次数增加loss变小,最后趋于稳定为0.9996225833892822
智能推荐
PhpStrom2018的激活范式_phpstrom2018.2.3-程序员宅基地
文章浏览阅读409次。1:找到windows-》System32-》drivers-》etc-》host-》配置域名(0.0.0.0 account.jetbrains.com)2:打开浏览器http://idea.lanyus.com/ 获取注册码3:复制注册码 ,注册时切换至Activation Code选项4:OK。_phpstrom2018.2.3
3dmax渲染有噪点的六大原因及解决方案_3dmax噪点多怎么解决-程序员宅基地
文章浏览阅读261次。原因:环境阻光(AO)的设置不当,导致模型结构转变处产生过多的暗部阴影,从而使渲染图像呈现出颗粒感和模糊。原因:3dmax中的材质细分不够,影响渲染效果,导致图像出现颗粒感和噪点。原因:3dmax中的图像尺寸过低,导致渲染后的效果图呈现出颗粒感和噪点。原因:发光贴图和灯光缓存的设置不当,导致渲染图像出现颗粒感和噪点。原因:3dmax中的主光源灯光细分不够,导致渲染图像有颗粒感。原因:DMC采样的参数设置不合理,导致渲染图像出现噪点。按照这些设置,通常可以避免图像出现噪点。,从而避免渲染后的模糊和噪点。_3dmax噪点多怎么解决
前端渲染CSR和SSR的结合使用分析_next同时使用ssr与csr-程序员宅基地
文章浏览阅读1.2k次。我们都知道,以往的CSR(客户端浏览器渲染)多多少少会有一点点SEO问题,不只是SPA(单页面应用程序),只不过SPA的SEO问题比较严重,一般的前端项目有很多个页面,渲染的压力是分散的,所以页面渲染速度很快,基本够爬虫抓到很多内容,但SPA只有一个页面。而我们的SSR(服务器渲染)可以弥补像SPA项目的SEO(搜索引擎优化) 不友好问题。但是它本身对比CSR也是有不足的。所以,为什么不可以结合它们两个的优点去进行使用呢?_next同时使用ssr与csr
2022-IOS-For-Fun_um-ios 2022-程序员宅基地
文章浏览阅读503次。2022 IOS Developer for funBasic stuffComputer Science fundamentalsMain parts of a computer system - CPU, memory, storageHow Operating System worksWhat is a databaseHow Internet worksGit version controlObject Oriented ProgrammingThe setupMacOSHomeb_um-ios 2022
PHP中的循环描述错误有哪些_PHP关于while循环中修改选取条件出现的错误-程序员宅基地
文章浏览阅读109次。业务需求是:读取某个表中每一行的的字段A、B、C的值如果C的值是0,就改成1或者2代码大概是这么写的:$query = "SELECT * FROM table WHERE C = 0";$result = mysqli_query($link, $query);if($result){while ($rows = mysqli_fetch_array($result)){if (判断条件为tru..._while循环报错php
ionic介绍-程序员宅基地
文章浏览阅读3.4k次。最近公司在使用ionic做混合APP,虽然是最后端,但是也查一下东西,介绍一下吧这是菜鸟教程的Ionic一.介绍ionic是一种老式的使用H5开发iOS和Android应用的方式,也可以使用新的语言React Native开发,当然对于H5实现复杂的或者交互性没有那么好的,就可以使用iOS和Android的插件实现;二.Ionic特点a.开发方面:1.ionic 基于Angular..._ionic
随便推点
vue基于element-ui的Select选择器实现的动态多级联动下拉选择_element-ui select 级联-程序员宅基地
文章浏览阅读2w次,点赞6次,收藏26次。demo地址代码如下:Html<div id="app"> <el-select v-for="(arrItem,key) in selectList" :key="key" v-model="selectArr[key]" filterable placeholder="请选择" value-key="value" @change="selected" @focu..._element-ui select 级联
LeetCode——76. 最小覆盖子串_leetcode最小覆盖子串-程序员宅基地
文章浏览阅读123次。76. 最小覆盖子串_leetcode最小覆盖子串
Oracle 常用语句_oracle查询导入目录常用语句-程序员宅基地
文章浏览阅读112次。https://download.csdn.net/download/u014096024/21109113oracle练习1.如何查询一个角色包括的权限 a.一个角色包含的系统权限 select * from dba_sys_privs where grantee='DBA'; b.一个角色包含的对象权限2.oracle究竟有多少种角色 (查询oracle中所有的角色,一般是dba) select * from dba_roles;3.查询o..._oracle查询导入目录常用语句
数据可视化之美:经典案例与实践解析_数据可视化经典-程序员宅基地
文章浏览阅读9.3k次,点赞25次,收藏93次。随着DT时代的到来,传统的统计图表很难对复杂数据进行直观地展示。这几年数据可视化作为一个新研究领域也变得越来越火。成功的可视化,如果做得漂亮,虽表面简单却富含深意,可以让观测者一眼就能洞察事实并产生新的理解。可视化(visualization)和可视效果(visual)两个词是等价的,表示所有结构化的信息表现方式,包括图形、图表、示意图、地图、故事情节图以及不是很正式的结构化插图。基本的可视化展..._数据可视化经典
8086汇编4位bcd码_[走近FPGA]之二进制转BCD码-程序员宅基地
文章浏览阅读1.3k次。注:本文由不愿透露姓名的 @Bulingxx 撰写。以下为正文。在上一篇文章中介绍了数码管如何在FPGA开发板上实现动态显示,其文章链接如下:人生状态机:[走近FPGA]之数码管动态显示zhuanlan.zhihu.com本文的所有实例都使用硬木课堂Xilinx Aritx 7 FPGA板实现,且附有上板演示视频,该开发板的链接如下:硬木课堂 Xilinx Aritx 7 FPGA板 Arm C..._8086汇编语言 实现二进制数到bcd码的转换
使用nfs之后初始化mysql失败_influxdb数据库 nfs存储初始化失败-程序员宅基地
文章浏览阅读1.7k次。将nfs作为mysql的数据目录输出后,在另一台主机上启动mysql进程时,会出现如下这样的错误,究其原因,其实还是nfs自身设计的缺陷。 初始化就是使用特定的用户,去特定的目录去更新mysql,虽然说添加mysql用户之后,所有的对数据的修改权限都是以mysql用户执行的,而且nfs的数据目录也都设计成了mysql,常理是没有问题的。但是,执行mysql_ins_influxdb数据库 nfs存储初始化失败