详解 | Dubbo 的 5 个分之和 3 大新特性-程序员宅基地

Apache Dubbo Meetup · 南京站
本文是对 Apache Dubbo Meetup 南京站演讲嘉宾徐靖峰(花名:岛风)分享内容的回顾,首发于「Kirito的技术分享」,阿里巴巴中间件受权转载。
Dubbo 分支
Dubbo 目前有如图所示的 5 个分支,其中 2.7.1-release 只是一个临时分支,忽略不计,对其他 4 个分支进行介绍。
2.5.x 近期已经通过投票,Dubbo 社区即将停止对其的维护。
2.6.x 为长期支持的版本,也是 Dubbo 贡献给 Apache 之前的版本,其包名前缀为:com.alibaba,JDK 版本对应 1.6。
3.x-dev 是前瞻性的版本,对 Dubbo 进行一些高级特性的补充,如支持 rx 特性。
master 为长期支持的版本,版本号为 2.7.x,也是 Dubbo 贡献给 Apache 的开发版本,其包名前缀为:org.apache,JDK 版本对应 1.8。
如果想要研究 Dubbo 的源码,建议直接浏览 master 分支。
Dubbo 2.7 新特性
Dubbo 2.7.x 作为 Apache 的孵化版本,除了对代码进行优化之外,还新增了许多重磅的新特性,本文将介绍其中最典型的三个新特性:
异步化改造
三大中心改造
服务治理增强
异步化改造
4 种调用方式
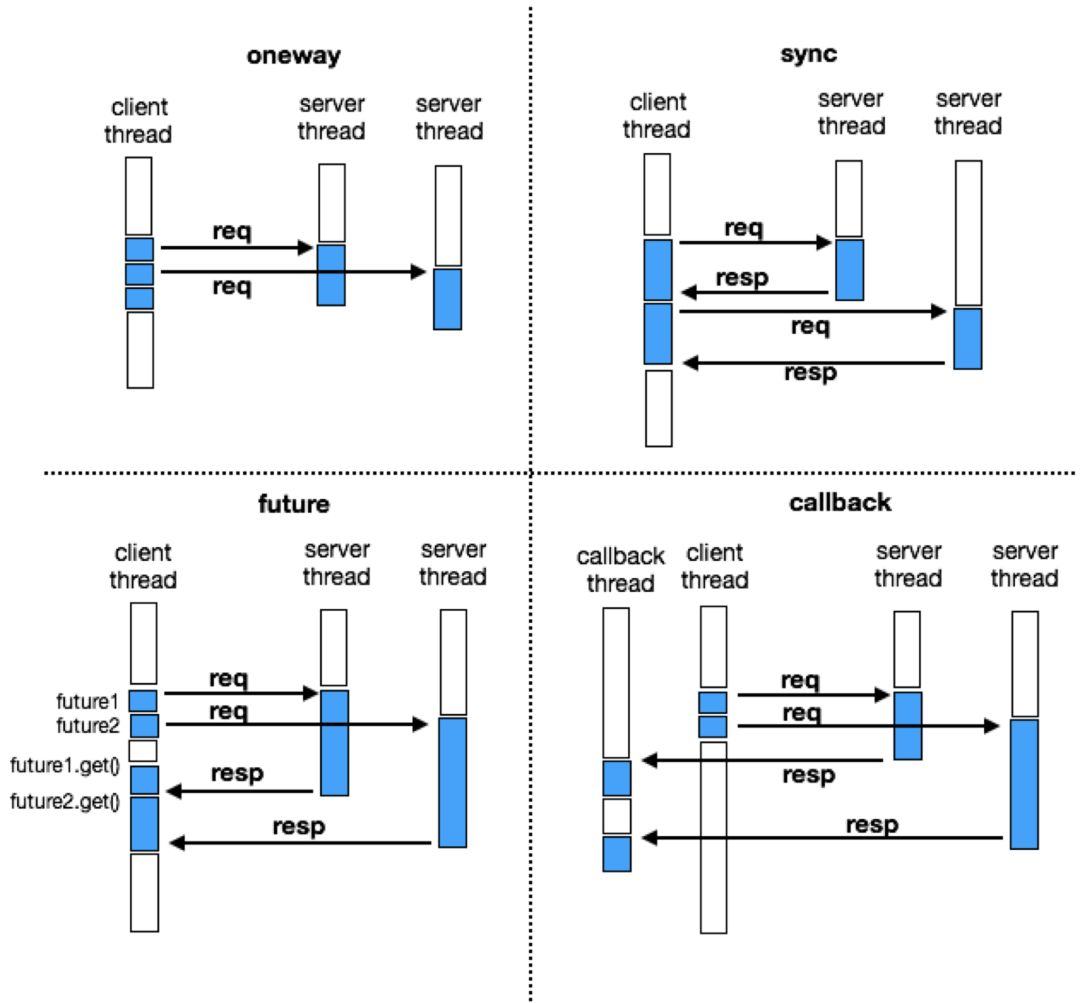
在远程方法调用中,大致可以分为这 4 种调用方式。
oneway 指的是客户端发送消息后,不需要接受响应。对于那些不关心服务端响应的请求,比较适合使用 oneway 通信。
注意,void hello() 方法在远程方法调用中,不属于 oneway 调用,虽然 void 方法表达了不关心返回值的语义,但在 RPC 层面,仍然需要做通信层的响应。
sync 是最常用的通信方式,也是默认的通信方法。
future 和 callback 都属于异步调用的范畴,他们的区别是:在接收响应时,future.get() 会导致线程的阻塞;callback 通常会设置一个回调线程,当接收到响应时,自动执行,不会对当前线程造成阻塞。
Dubbo 2.6 异步化
异步化的优势在于,客户端不需要启动多线程即可完成并行调用多个远程服务,相比于多线程,异步化开销较小。
介绍 2.7 中的异步化改造之前,先回顾一下如何在 2.6 中使用 Dubbo 异步化的能力。
将同步接口声明成 async=true
<dubbo:reference id="asyncService" interface="org.apache.dubbo.demo.api.AsyncService" async="true"/>public interface AsyncService {
String sayHello(String name);
}通过上下文类获取 future
AsyncService.sayHello("Han Meimei");
Future<String> fooFuture = RpcContext.getContext().getFuture();
fooFuture.get();可以看出,这样的使用方式,不太符合异步编程的习惯,竟然需要从一个上下文类中获取到 Future。如果同时进行多个异步调用,使用不当很容易造成上下文污染。而且,Future 并不支持 callback 的调用方式。这些弊端在 Dubbo 2.7 中得到了改进。
Dubbo 2.7 异步化
无需配置中特殊声明,显示声明异步接口即可
public interface AsyncService {
String sayHello(String name);
default CompletableFuture<String> sayHiAsync(String name) {
return CompletableFuture.completedFuture(sayHello(name));
}
}使用 callback 方式处理返回值
CompletableFuture<String> future = asyncService.sayHiAsync("Han MeiMei");
future.whenComplete((retValue, exception) -> {
if (exception == null) {
System.out.println(retValue);
} else {
exception.printStackTrace();
}
});Dubbo 2.7 中使用了 JDK1.8 提供的 CompletableFuture 原生接口对自身的异步化做了改进。 CompletableFuture 可以支持 future 和 callback 两种调用方式,用户可以根据自己的喜好和场景选择使用,非常灵活。
异步化设计 FAQ
Q:如果 RPC 接口只定义了同步接口,有办法使用异步调用吗?
A:2.6 中的异步调用唯一的优势在于,不需要在接口层面做改造,又可以进行异步调用,这种方式仍然在 2.7 中保留;使用 Dubbo 官方提供的 compiler hacker,编译期自动重写同步方法,请在此[1]讨论和跟进具体进展。
Q:关于异步接口的设计问题,为何不提供编译插件,根据原接口,自动编译出一个 XxxAsync 接口?
A:Dubbo 2.7 采用采用过这种设计,但接口的膨胀会导致服务类的增量发布,而且接口名的变化会影响服务治理的一些相关逻辑,改为方法添加 Async 后缀相对影响范围较小。
Q:Dubbo 分为了客户端异步和服务端异步,刚刚你介绍的是客户端异步,为什么不提服务端异步呢?
A:Dubbo 2.7 新增了服务端异步的支持,但实际上,Dubbo 的业务线程池模型,本身就可以理解为异步调用,个人认为服务端异步的特性较为鸡肋。
三大中心改造
三大中心指的:注册中心,元数据中心,配置中心。
在 2.7 之前的版本,Dubbo 只配备了注册中心,主流使用的注册中心为 ZooKeeper。新增加了元数据中心和配置中心,自然是为了解决对应的痛点,下面我们来详细阐释三大中心改造的原因。
元数据改造
元数据定义为描述数据的数据,在服务治理中,例如服务接口名、重试次数和版本号等等,都可以理解为元数据。在 2.7 之前,元数据一股脑丢在了注册中心,这造成了一系列的问题:
推送量大 -> 存储数据量大 -> 网络传输量大 -> 延迟严重
生产者端注册 30+ 参数,有接近一半是不需要作为注册中心进行传递的;消费者端注册 25+ 参数,只有个别需要传递给注册中心。
有了以上的理论分析,Dubbo 2.7 进行了大刀阔斧的改动,只将真正属于服务治理的数据发布到注册中心之中,大大降低了注册中心的负荷。
同时,将全量的元数据发布到另外的组件中:元数据中心。元数据中心目前支持 Redis(推荐),ZooKeeper。这也为 Dubbo 2.7 全新的 Dubbo Admin 做了准备,关于新版的 Dubbo Admin,我将会后续准备一篇独立的文章进行介绍。
示例:使用 ZooKeeper 作为元数据中心:
<dubbo:metadata-report address="zookeeper://127.0.0.1:2181"/>Dubbo 2.6 元数据
dubbo://30.5.120.185:20880/com.alibaba.dubbo.demo.DemoService?
anyhost=true&
application=demo-provider&
interface=com.alibaba.dubbo.demo.DemoService&
methods=sayHello&
bean.name=com.alibaba.dubbo.demo.DemoService&
dubbo=2.0.2&
executes=4500&
generic=false&
owner=kirito&
pid=84228&
retries=7&
side=provider&
timestamp=1552965771067从本地的 ZooKeeper 中取出一条服务数据,通过解码之后,可以看出,的确有很多参数是不必要。
Dubbo 2.7 元数据
在 2.7 中,如果不进行额外的配置,ZooKeeper 中的数据格式仍然会和 Dubbo 2.6 保持一致,这主要是为了保证兼容性,让 Dubbo 2.6 的客户端可以调用 Dubbo 2.7 的服务端。如果整体迁移到 2.7,则可以为注册中心开启简化配置的参数:
<dubbo:registry address=“zookeeper://127.0.0.1:2181” simplified="true"/>Dubbo 将会只上传那些必要的服务治理数据,一个简化过后的数据如下所示:
dubbo://30.5.120.185:20880/org.apache.dubbo.demo.api.DemoService?
application=demo-provider&
dubbo=2.0.2&
release=2.7.0&
timestamp=1552975501873对于那些非必要的服务信息,仍然全量存储在元数据中心之中:

元数据中心的数据可以被用于服务测试,服务 MOCK 等功能。目前注册中心配置中 simplified 的默认值为 false,因为考虑到了迁移的兼容问题,在后续迭代中,默认值将会改为 true。
配置中心支持
衡量配置中心的必要性往往从三个角度出发:
分布式配置统一管理
动态变更推送
安全性
Spring Cloud Config,Apollo,Nacos 等分布式配置中心组件都对上述功能有不同程度的支持。
在 2.7 之前的版本中,ZooKeeper 中设置了部分节点:configurators 和 routers,用于管理部分配置和路由信息,它们可以理解为 Dubbo 配置中心的雏形。在 2.7 中,Dubbo 正式支持了配置中心开源组件,目前支持的几种配置中心有:ZooKeeper,Apollo,Nacos(2.7.1-release 支持)。
在 Dubbo 中,配置中心主要承担了两个作用:
外部化配置。启动配置的集中式存储;
服务治理。服务治理规则的存储与通知;
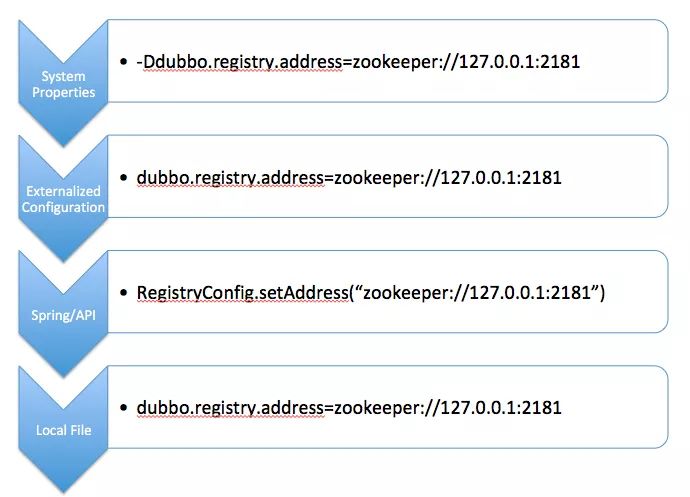
示例:使用 ZooKeeper 作为配置中心
<dubbo:config-center address="zookeeper://127.0.0.1:2181"/>引入配置中心后,需要注意配置项的覆盖问题,优先级如图所示:
服务治理增强
我更倾向于将 Dubbo 当做一个服务治理框架,而不仅仅是一个 RPC 框架。
在 2.7 中,Dubbo 对其服务治理能力进行了增强,增加了标签路由的能力,并抽象出了应用路由和服务路由的概念。在最后一个特性介绍中,着重对标签路由 TagRouter 进行探讨。
在服务治理中,路由层和负载均衡层的对比。区别 1,Router:m 选 n,LoadBalance:n 选 1;区别 2,路由往往是叠加使用的,负载均衡只能配置一种。
在很长的一段时间内,Dubbo 社区经常有人提的一个问题是:Dubbo 如何实现流量隔离和灰度发布,直到 2.7 提供了标签路由,用户可以使用这个功能,来实现上述的需求。
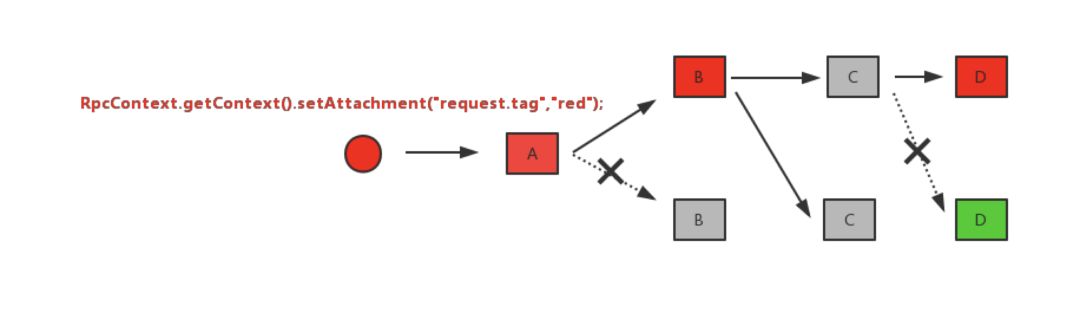
标签路由提供了这样一个能力:当调用链路为 A -> B -> C -> D 时,用户给请求打标,最典型的打标方式可以借助 attachment(他可以在分布式调用中传递下去),调用会优先请求那些匹配的服务端,如 A -> B,C -> D,由于集群中未部署 C 节点,则会降级到普通节点。
打标方式会收到集成系统差异的影响,从而导致很大的差异,所以 Dubbo 只提供了 RpcContext.getContext().setAttachment() 这样的基础接口,用户可以使用 SPI 扩展,或者 server filter 的扩展,对测试流量进行打标,引导进入隔离环境/灰度环境。
新版的 Dubbo Admin 提供了标签路由的配置项:
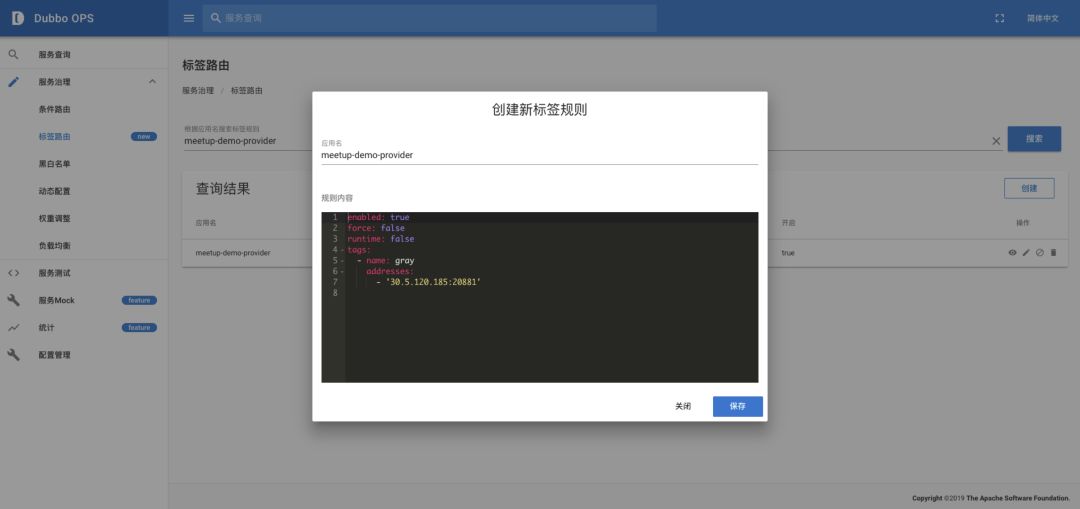
Dubbo 用户可以在自己系统的基础上对标签路由进行二次扩展,或者借鉴标签路由的设计,实现自己系统的流量隔离,灰度发布。
总结
本文介绍了 Dubbo 2.7 比较重要的三大新特性:异步化改造,三大中心改造,服务治理增强。此外,Dubbo 2.7 还包含了很多功能优化、特性升级,可以在项目源码的 CHANGES.md[2] 中浏览全部的改动点。最后,提供一份 Dubbo 2.7 的升级文档:2.7迁移文档[3],欢迎体验。
相关链接:
[1] compile hacker
https://github.com/dubbo/dubbo-async-processor#compiler-hacker-processer
[2] CHANGES.md
https://github.com/apache/incubator-dubbo/blob/master/CHANGES.md
[3] 2.7迁移文档
http://dubbo.incubator.apache.org/zh-cn/docs/user/versions/version-270.html
本文作者:
徐靖峰(花名:岛风)
GitHub ID lexburner,阿里巴巴高级开发工程师,负责阿里巴巴服务治理框架的研发工作,关注微服务、服务治理和软件设计等领域。
文章缩略图
Photo by Cody Davis on Unsplash
/ Dubbo x 网易考拉? /

每周一推
第一时间获得下期分享
☟☟☟
Tips:
# 点下“在看”️
# 然后,公众号对话框内发送“Polo衫”,试试手气??
# 本期奖品是 Aliware 定制 Polo衫。
智能推荐
蓝凌EIS智慧协同平台saveImg接口存在任意文件上传漏洞_蓝凌eis智慧协同平台文件上传漏洞-程序员宅基地
文章浏览阅读979次。蓝凌智慧协同平台eis集合了非常丰富的模块,满足组织企业在知识、协同、项目管理系统建设等需求。_蓝凌eis智慧协同平台文件上传漏洞
LLaVA-1.5-程序员宅基地
文章浏览阅读193次。与InstructBLIP或Qwen-VL在数亿甚至数十几亿的图像文本配对数据上训练的、专门设计的视觉重新采样器相比,LLaVA用的是最简单的LMM架构设计,只需要在600K个图像-文本对上,训练一个简单的完全连接映射层即可。结果表明,LLaVA-1.5不仅可以使用更少的预训练和指令微调数据,而且还可以利用最简单的架构、学术计算和公共数据集来实现最佳的性能——在12个基准中的11个上取得了SOTA。为了解决这个问题,研究人员建议在VQA问题的末尾,添加一个可以明确输出格式的提示,进而让模型生成简短回答。
ORACLE基本数据类型总结_oracle 数值类型最大值-程序员宅基地
文章浏览阅读442次。2013-08-17 21:04 by 潇湘隐者, 100246 阅读, 5 评论, 收藏, 编辑 ORACLE基本数据类型(亦叫内置数据类型 built-in datatypes)可以按类型分为:字符串类型、数字类型、日期类型、LOB类型、LONG RAW& RAW类型、ROWID & UROWID类型。在讲叙字符串类型前,先要讲一下编码。字符串类型的数据可依编码方式分成_oracle 数值类型最大值
10种机器学习算法_决策树和mlp-程序员宅基地
文章浏览阅读315次。作为数据科学家的实践者,我们必须了解一些通用机器学习的基础知识算法,这将帮助我们解决所遇到的新领域问题。本文对通用机器学习算法进行了简要的阐述,并列举了它们的相关资源,从而帮助你能够快速掌握其中的奥妙。▌1.主成分分析(PCA)/ SVDPCA是一种无监督的方法,用于对由向量组成的数据集的全局属性进行理解。本文分析了数据点的协方差矩阵,以了解哪些维度(大部分情况)/数据点(少数情况)更为重要,即它..._决策树和mlp
桥接模式的实现-程序员宅基地
文章浏览阅读148次。在这个示例中,我们使用std::shared_ptr来管理Implementor对象的生命周期,确保在不再需要时自动释放资源。通过智能指针的使用,我们避免了手动管理内存的复杂性,提高了代码的可靠性和可维护性。希望这个示例能帮助你理解如何使用智能指针来实现桥接模式。当使用智能指针来实现桥接模式时,我们可以利用std::shared_ptr或std::unique_ptr来管理对象的生命周期,确保资源的正确释放。
制造业敏感文件外发不安全?一招解锁更高效的加密方式!-程序员宅基地
文章浏览阅读440次,点赞11次,收藏8次。云盒子在制造业上有丰富的部署经验,在面向制造类企业的重要文件,可以通过审计、授权、文件加密进行多重保护,使得图纸文件、专利技术、采购订单等敏感数据等到有效保护,做到无处可泄,同时安全可靠,也不会对日常工作效率有影响 ,实现真正有效的企业文件保护的目的,达到既防止机密文件外泄和扩散,又支持内部知识积累和文件共享的目的。云盒子的加密方式是通过将本地文件数据上传到云盘进行统一加密存储,而不是对设备加密,通过【本地加密】+【云加密】双重组合下,不管用什么设备打开文件都受到管控,使管理者管理起来能够更高效。
随便推点
计算几何讲义——计算几何中的欧拉定理-程序员宅基地
文章浏览阅读188次。在处理计算几何的问题中,有时候我们会将其看成图论中的graph图,结合我们在图论中学习过的欧拉定理,我们可以通过图形的节点数(v)和边数(e)得到不是那么好求的面数f。 平面图中的欧拉定理: 定理:设G为任意的连通的平面图,则v-e+f=2,v是G的顶点数,e是G的边数,f是G的面数。证明:其实有点类似几何学中的欧拉公式的证明方法,这里采用归纳证明的方法。对m..._怎么证明平面图欧拉定理
c语言中各种括号的作用,C语言中各种类型指针的特性与用法介绍-程序员宅基地
文章浏览阅读750次。C语言中各种类型指针的特性与用法介绍本文主要介绍了C语言中各种类型指针的特性与用法,有需要的朋友可以参考一下!想了解更多相关信息请持续关注我们应届毕业生考试网!指针为什么要区分类型:在同一种编译器环境下,一个指针变量所占用的内存空间是固定的。比如,在16位编译器环境 下,任何一个指针变量都只占用8个字节,并不会随所指向变量的类型而改变。虽然所有的指针都只占8个字节,但不同类型的变量却占不同的字节数..._c语言带括号指针
缅甸文字库 缅甸语字库 缅甸字库算法_0x103c-程序员宅基地
文章浏览阅读9.5k次。字库交流 QQ:2229691219 缅甸语比较特殊、缅甸语有官方和民间之分,二者不同的是编码机制不同,因此这2种缅甸语的字串翻译、处理引擎、字库都是不同的。我们这里只讨论官方语言。 缅文、泰文等婆罗米系文字大多是元音附标文字,一般辅音字母自带默认元音可以发音,真正拼写词句时元音像标点符号一样附标在辅音上下左右的相应位置。由于每个元音位于辅音的具体位置是有自己的规则的,当只书写..._0x103c
Python+django+vue校园二手闲置物品拍卖系统pycharm毕业设计项目推荐_基于python+django+vue实现的校园二手交易平台-程序员宅基地
文章浏览阅读200次。在校园,随着学生数量的增多,存在许多生活和学习物品,许多学习用品经过一学期学习之后往往被闲置,一些出于一时喜欢而购买的物品使用机会少而被闲置,还有一些物品以低廉的价格卖给资源回收站,造成巨大的资源浪费。校园闲置物品拍卖系统使用python技术,MySQL数据库进行开发,系统后台使用django框架进行开发,具有低耦合、高内聚的特点,其中校园用户通过人脸识别的方法增加系统安全性,在闲置物品推荐中,使用协同过滤算法进行商品推荐。系统的开发,帮助高校有效的对闲置物品进行管理,提高了闲置物品销售的效率。_基于python+django+vue实现的校园二手交易平台
【推荐系统论文精读系列】(十)--Wide&Deep Learning for Recommender Systems_引用《wide & deep learning for recommender systems》-程序员宅基地
文章浏览阅读1.1k次,点赞3次,收藏3次。文章目录Wide & Deep Learning for Recommender Systems一、摘要二、介绍三、推荐系统综述四、Wide&Deep学习4.1 Wide部分4.2 Deep部分4.3 联合训练 Wide&Deep ModelPreferenceWide & Deep Learning for Recommender Systems一、摘要具有非线性特征转化能力的广义线性模型被广泛用于大规模的分类和回归问题,对于那些输入数据是极度稀疏的情况下。通过使用交_引用《wide & deep learning for recommender systems》
c++ sleep函数_Linux 多线程应用中如何编写安全的信号处理函数-程序员宅基地
文章浏览阅读171次。关于代码的可重入性,设计开发人员一般只考虑到线程安全,异步信号处理函数的安全却往往被忽略。本文首先介绍如何编写安全的异步信号处理函数;然后举例说明在多线程应用中如何构建模型让异步信号在指定的线程中以同步的方式处理。Linux 多线程应用中编写安全的信号处理函数在开发多线程应用时,开发人员一般都会考虑线程安全,会使用 pthread_mutex 去保护全局变量。如果应用中使用了信号,而且信号的产生不..._linux c++ sleep 不被中断